Jun-Hyun Bae, Wonyong Jo, Jaehyup Lee, Heechul Jung
Kyungpook National University
Presentation
Abstract
Text-to-image diffusion models utilize cross-attention to integrate textual information into the visual latent space, yet the transformation from text embeddings to latent features remains largely unexplored. We provide a mechanistic analysis of the output-value (OV) circuits within cross-attention layers through spectral analysis via singular value decomposition. Our analysis demonstrates that semantic concepts are encoded in low-dimensional subspaces spanned by singular vectors in OV circuits across cross-attention heads. To verify this, we intervene on concept-related components in the diffusion process, demonstrating that intervention on identified spectral components affects conceptual changes. We further validate these findings by examining visual outputs of isolated subspaces and their alignment with text embedding space. Through this mechanistic understanding, we demonstrate that simply nullifying these spectral components can achieve targeted concept removal with performance comparable to existing methods while providing interpretability.
Overview
We reveal how OV circuits in cross-attention transform text into visual features, and propose a retraining-free method for targeted concept removal.
- Spectral Decomposition — Decompose \(\mathbf{W}_{\text{OV}}\) via SVD to extract independent text-to-visual transformation pathways.
- Concept Localization — Discover that semantic concepts such as “Van Gogh style” or “nudity” concentrate in a small subset of spectral components.
- Spectral Nullification — Remove only these components to achieve targeted concept removal without retraining, matching existing methods.

Spectral isolation of each concept. Style retains only textures, lighting retains only edge glow, content retains full human form.
Method
The key mechanism that transforms text into visual features in cross-attention is the \(\mathbf{W}_{\text{OV}}\) matrix. Text embeddings organize semantic information along intrinsic axes, and \(\mathbf{W}_{\text{OV}}\) learns low-dimensional subspaces aligned with these axes to perform concept-specific transformations. Decomposing this matrix via SVD yields spectral components that each serve as independent text-to-visual pathways, and semantic concepts like “Van Gogh style” or “nudity” concentrate in a small subset of these components.
Only about 10% of all heads contribute highly to any given concept, and scaling their outputs modulates the concept’s intensity.

Scaling the output of high-contribution heads (~10% of all heads) for the "Van Gogh" concept with factor $\alpha$.
Operating at the spectral component level rather than the head level enables disentangled control over distinct concept dimensions such as style and content.

Spectral modulation (top) vs head-level modulation (bottom). Spectral components isolate style from other attributes.
The figure below shows the distribution of concept contributions across all heads. Most heads contribute minimally to any given concept, while a small number of heads carry the majority of the signal.
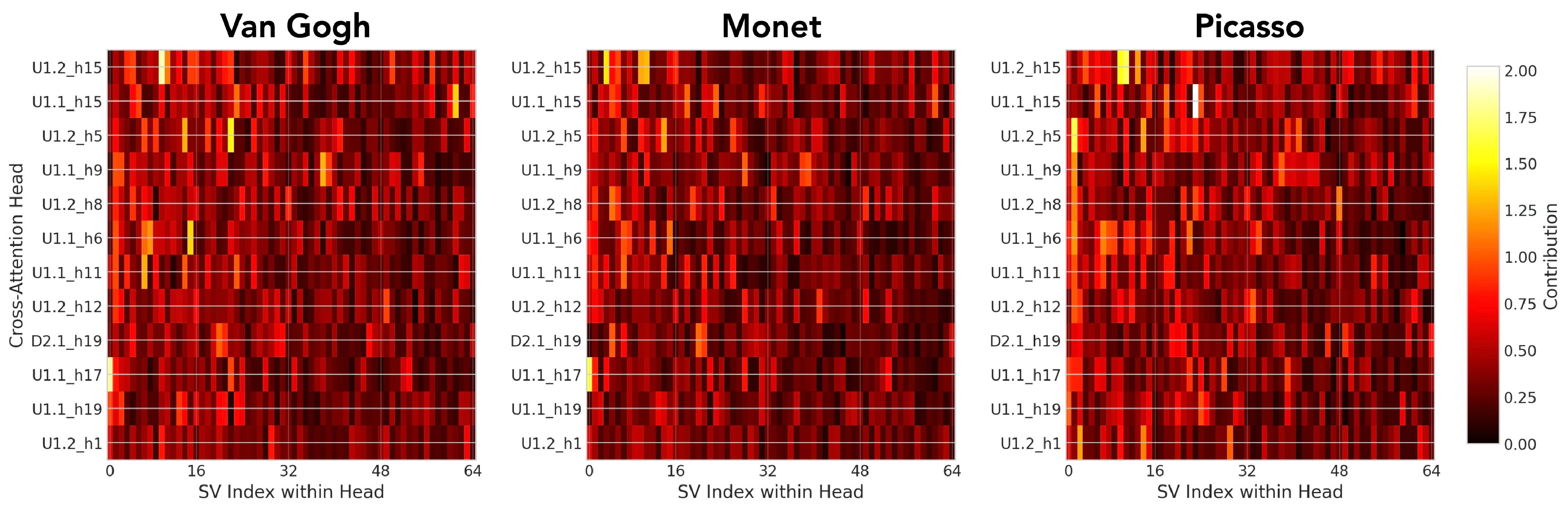
Distribution of concept contributions across heads. Concept information is concentrated in a small number of high-contribution heads.
Results
Quantitative
Spectral Nullification (SN) achieves concept removal performance comparable to retraining-based methods while preserving generation quality (CLIP score).
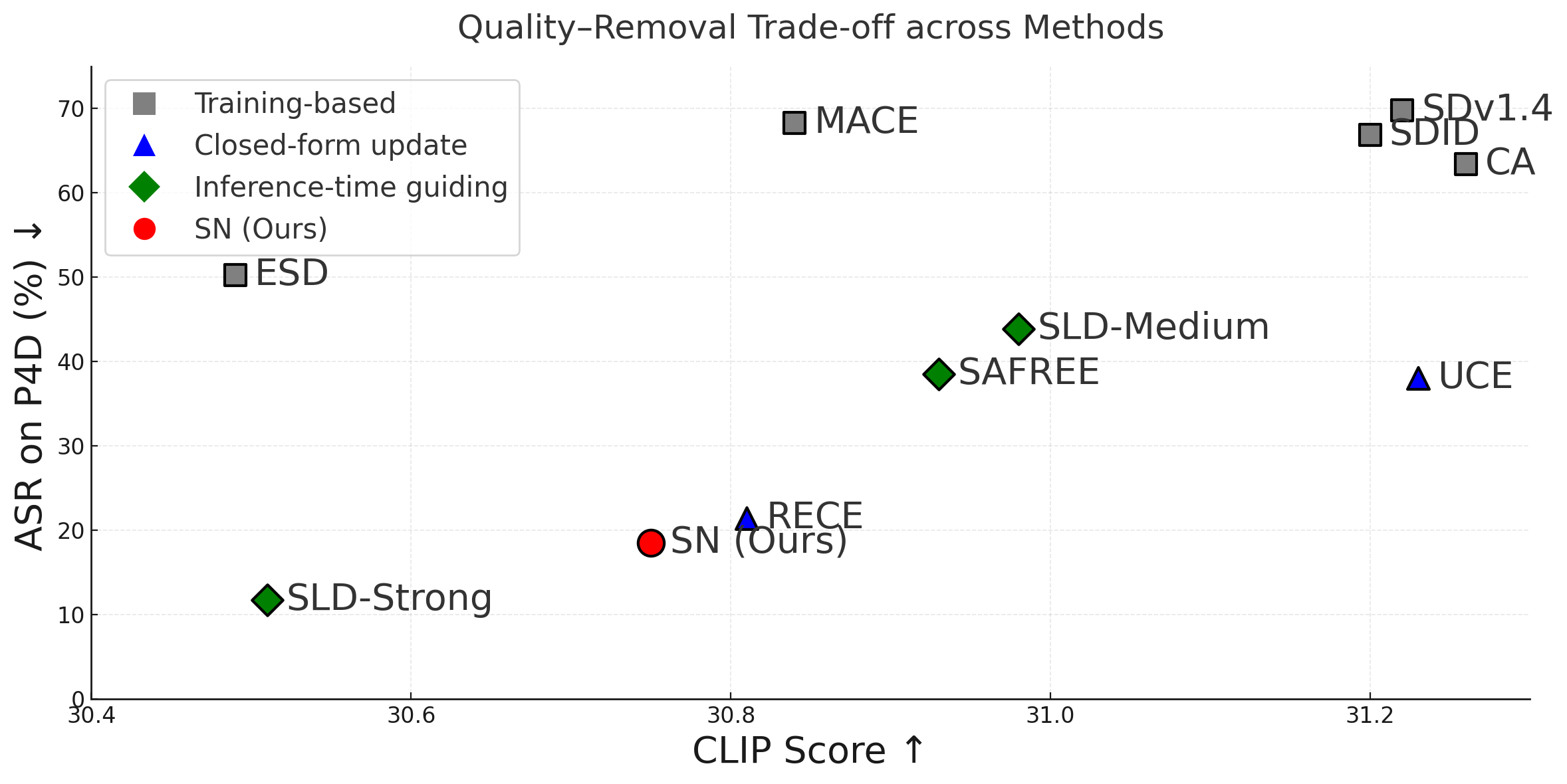
Concept removal vs generation quality (CLIP score). Spectral Nullification (SN) achieves comparable performance to existing methods without retraining.
To verify that concept-specific spectral components genuinely capture the semantics of their target concepts, we reconstruct text differences via spectral components and measure alignment with the CLIP vocabulary.
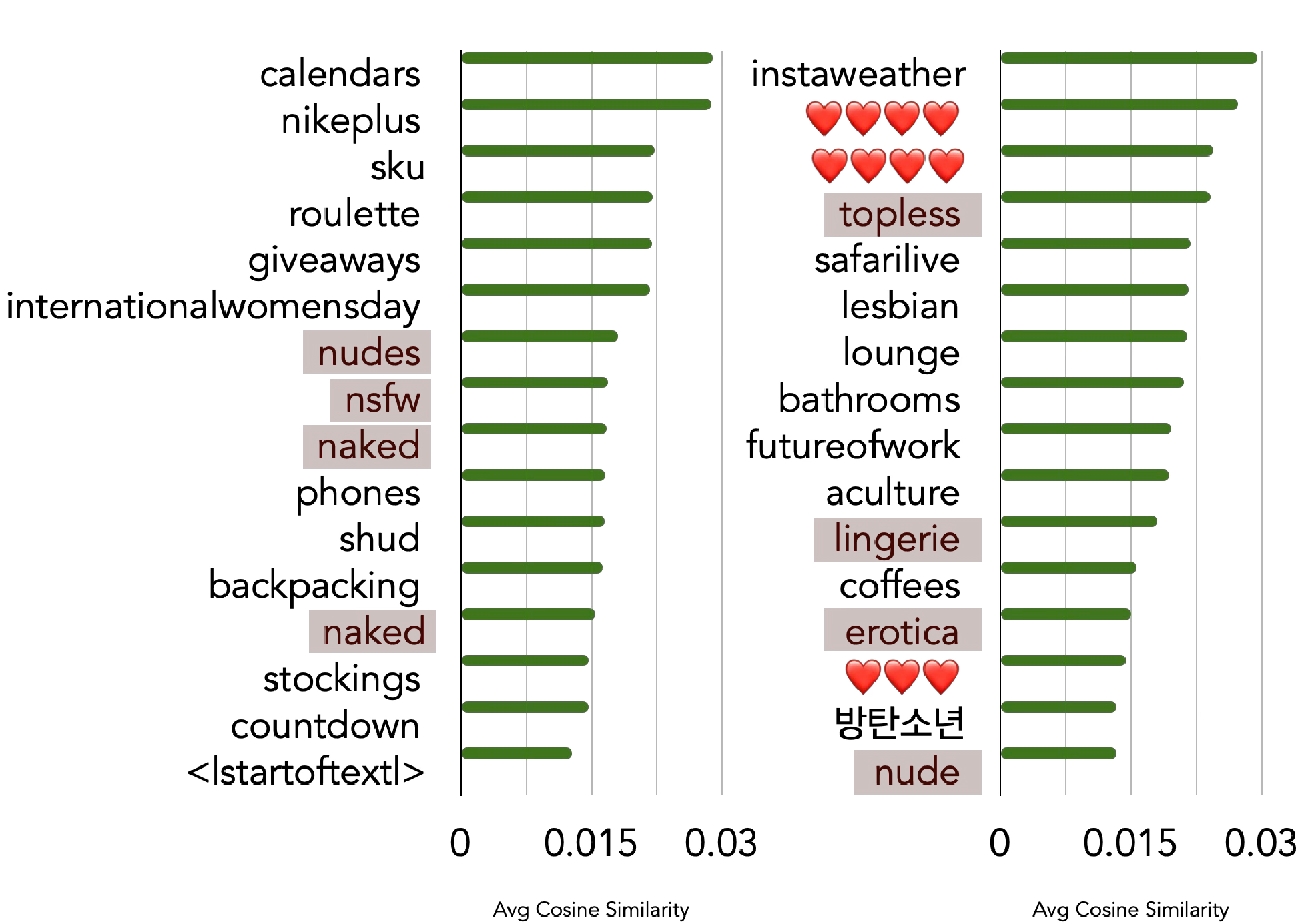
Reconstructing text differences via concept-specific spectral components and comparing against all 49,408 CLIP vocabulary tokens. Nudity-related tokens rank at the top.
We analyze whether concept subspaces across different heads share consistent structure using t-SNE and Jaccard similarity.
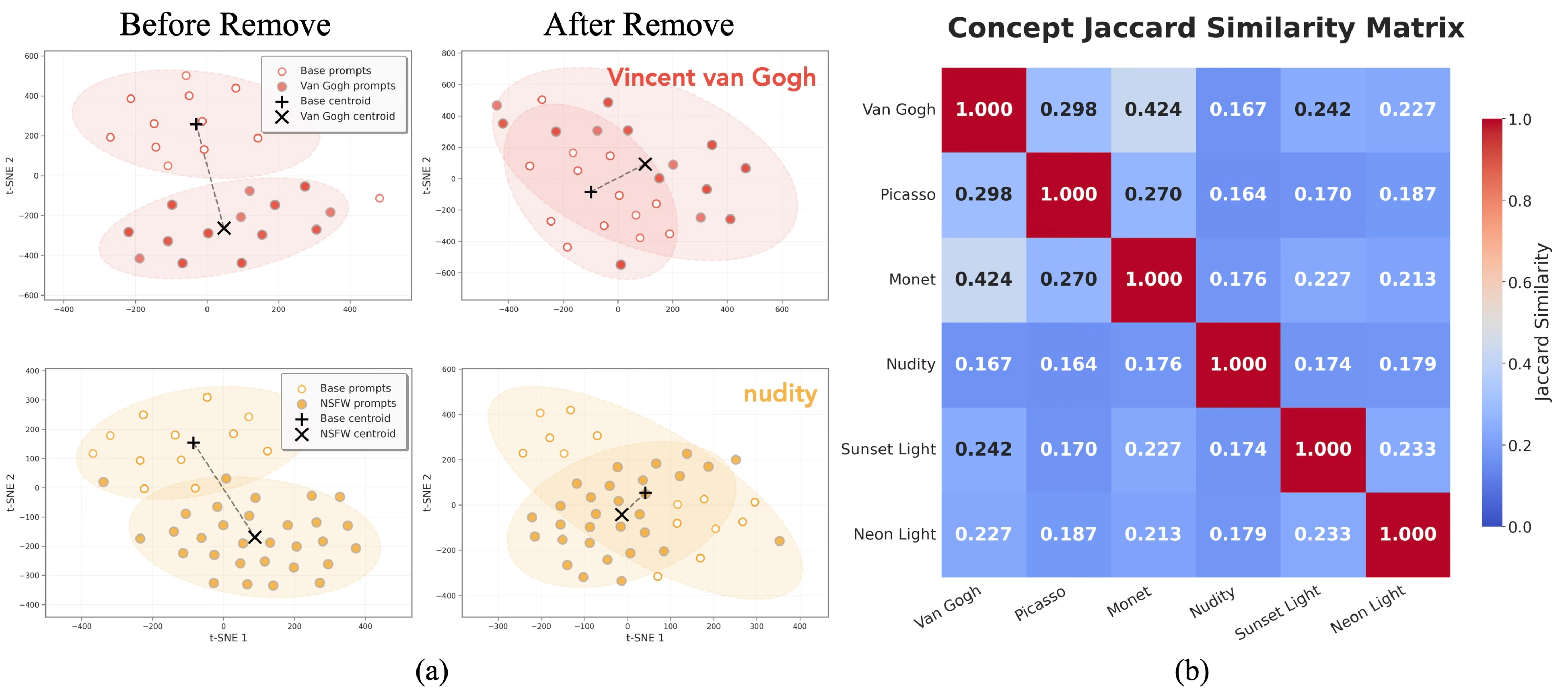
t-SNE visualization and Jaccard similarity of concept subspaces across heads. Subspaces for the same concept exhibit similar structure across heads.
Qualitative
Applying SN to adversarial prompts from the I2P benchmark effectively removes inappropriate content.

I2P benchmark with adversarial prompts. Left: SD v1.4 (before SN). Right: after SN.
BibTeX
@inproceedings{bae2026mechanistic,
title={Mechanistic Dissection of Cross-Attention Subspaces
in Text-to-Image Diffusion Models},
author={Bae, Jun-Hyun and Jo, Wonyong and Lee, Jaehyup
and Jung, Heechul},
booktitle={Proceedings of the AAAI Conference
on Artificial Intelligence},
year={2026}
}