Jun-Hyun Bae, Minho Lee, Heechul Jung
Kyungpook National University
Abstract
Training deep neural networks with empirical risk minimization (ERM) often captures dataset biases, hindering generalization to new or unseen data. Previous solutions either require prior knowledge of biases or utilize training intentionally biased models as auxiliaries; however, they still suffer from multiple biases. To address this, we introduce Adaptive Bias Discovery (ABD), a novel learning framework designed to mitigate the impact of multiple unknown biases. ABD trains an auxiliary model to be adapted to biases based on the debiased parameters from the debiasing phase, allowing it to navigate through multiple biases. Then, samples are reweighted based on the discovered biases to update debiased parameters. Extensive evaluations of synthetic experiments and real-world datasets demonstrate that ABD consistently outperforms existing methods, particularly in real-world applications where multiple unknown biases are prevalent.
Overview
We propose a learning framework that sequentially discovers and removes multiple biases in data without any prior bias information.
- Bias-adapted model — Generate a bias-sensitive auxiliary model \(f_\phi\) via one-step gradient descent from the debiased parameters \(\theta\) .
- Adaptive group formation — Partition data into a bias-aligned group (\(G^\odot\) ) and a bias-conflicting group (\(G^\otimes\) ) based on \(f_\phi\) ’s predictions.
- Iterative debiasing — Minimize worst-case group loss via group DRO; as \(\theta\) becomes robust to one bias, \(\phi\) naturally discovers the next.
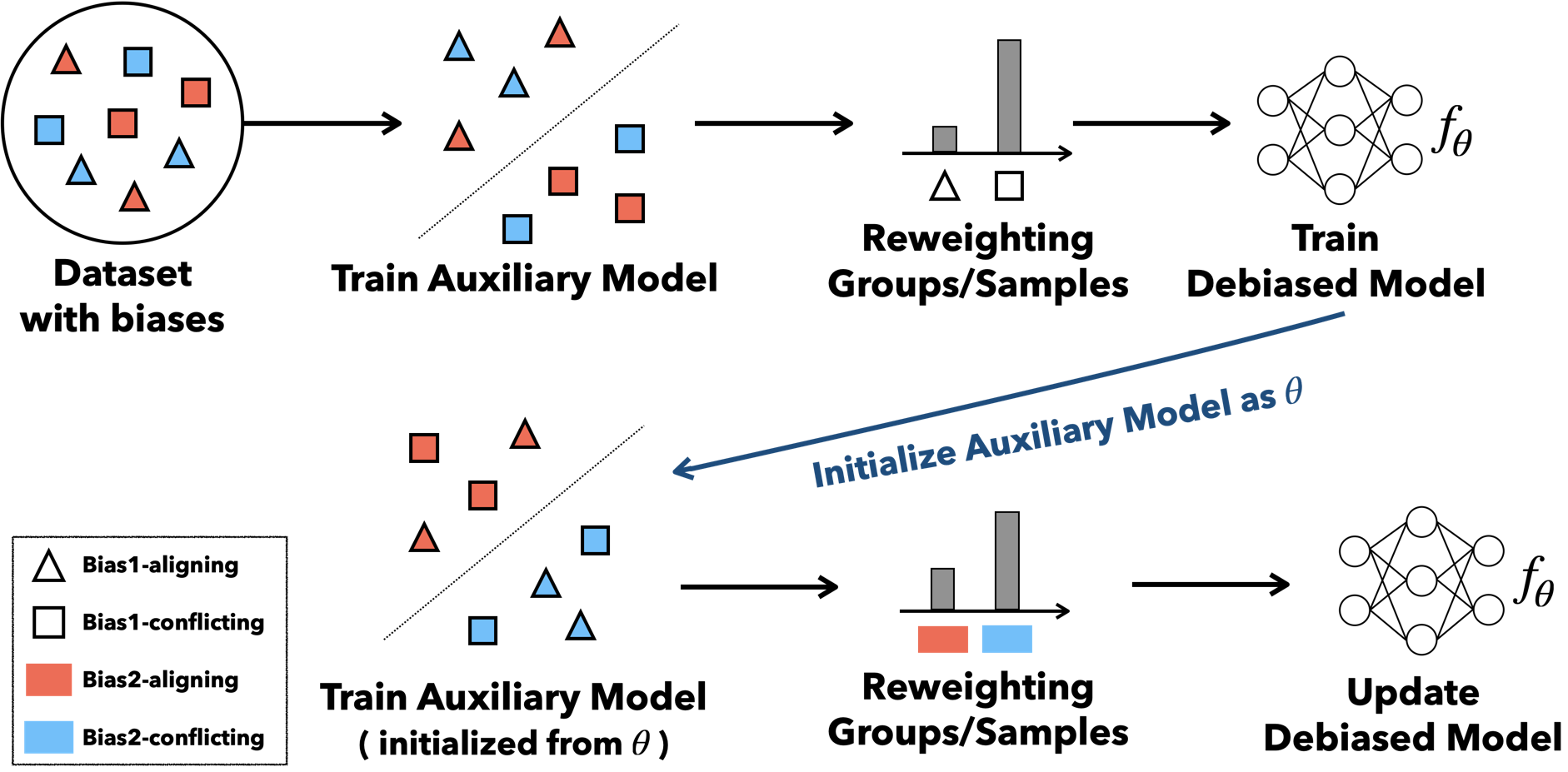
Overview of the ABD framework. Illustrated with two biases (Bias1, Bias2) and two learning steps.
Method
Models trained with ERM readily capture spurious correlations in the data, degrading generalization. Existing debiasing methods either require prior knowledge of biases or can only handle a single bias type.
ABD operates in two stages. First, bias-adapted parameters \(\phi = \theta - \alpha \nabla_\theta \mathcal{L}(f_\theta)\) are obtained via one-step gradient descent from the debiased parameters \(\theta\) . Since \(f_\phi\) is sensitive to superficial patterns, its predictions partition the data into a bias-aligned group (\(G^\odot\) ) and a bias-conflicting group (\(G^\otimes\) ). The debiased parameters \(\theta\) are then updated by minimizing the worst-case group loss via group DRO.
The key insight is that \(\phi\) is regenerated from \(\theta\) at every step. Once \(\theta\) becomes robust to the first bias, \(\phi\) naturally discovers the next most prominent bias. This MAML-like structure enables sequential discovery and removal of multiple biases without any prior bias information.
The GradCAM visualizations below show how the biased model \(f_\phi\) ’s attention shifts to different regions as training progresses, confirming that ABD adaptively discovers diverse biases during learning.

GradCAM visualizations of ERM and ABD's biased model $f_\phi$. As training progresses, $f_\phi$'s attention shifts to different bias features.
Results
Colored MNIST
OoD test accuracy (%). Single bias (Color) vs. multiple biases (Color & Patch).
| Algorithm | Color (OoD) | Color & Patch (OoD) |
|---|---|---|
| ERM | 16.4 | 14.0 |
| IRM | 66.9 | 13.4 |
| Group DRO | 13.6 | 14.1 |
| PI | 70.2 | 15.3 |
| ABD (Ours) | 70.7 | 62.3 |
| Optimal | 75.0 | 75.0 |
While PI only discovers the dominant bias (Color), ABD sequentially discovers multiple biases: Color first, then Patch.
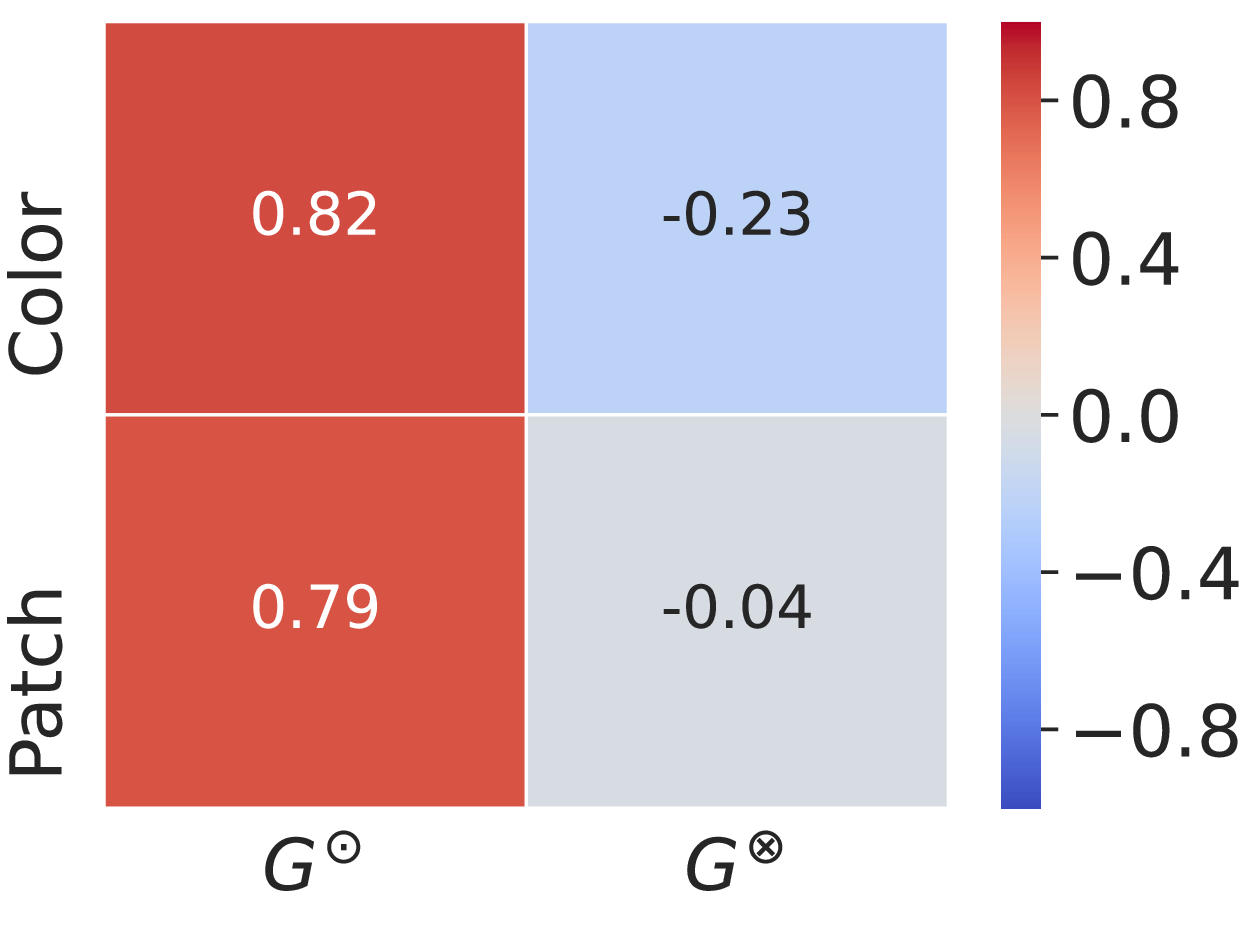
Pearson correlation coefficients within PI's groups. PI only discovers Color bias and fails to capture Patch.
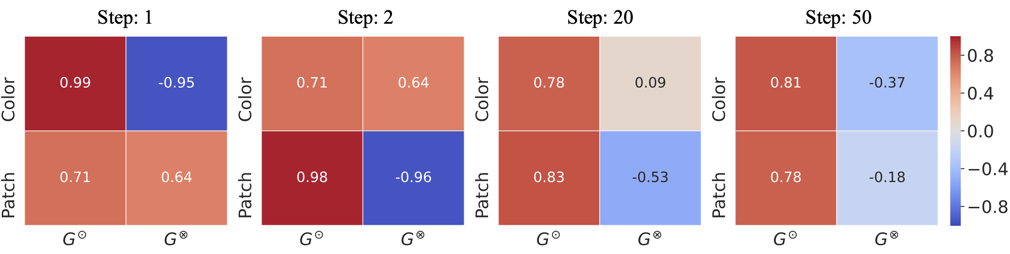
Pearson correlation coefficients within groups created by ABD. Biases are discovered sequentially: Color first, then Patch.
Real-World Tasks
CivilComments (worst-case acc.), MultiNLI (worst-case acc.), Camelyon17 (OoD acc.), FMoW (worst-region acc.).
| Algorithm | CivilComments | MultiNLI | Camelyon17 | FMoW |
|---|---|---|---|---|
| ERM | 56.0 | 61.8 | 70.3 | 32.3 |
| Group DRO | 70.0 | 62.7 | 68.4 | 30.8 |
| JTT | 69.3 | 63.2 | 63.8 | 33.4 |
| PI | 61.1 | 61.5 | 71.7 | 31.2 |
| LISA | — | — | 77.1 | 35.5 |
| ABD (Ours) | 71.1 | 67.1 | 81.1 | 34.1 |
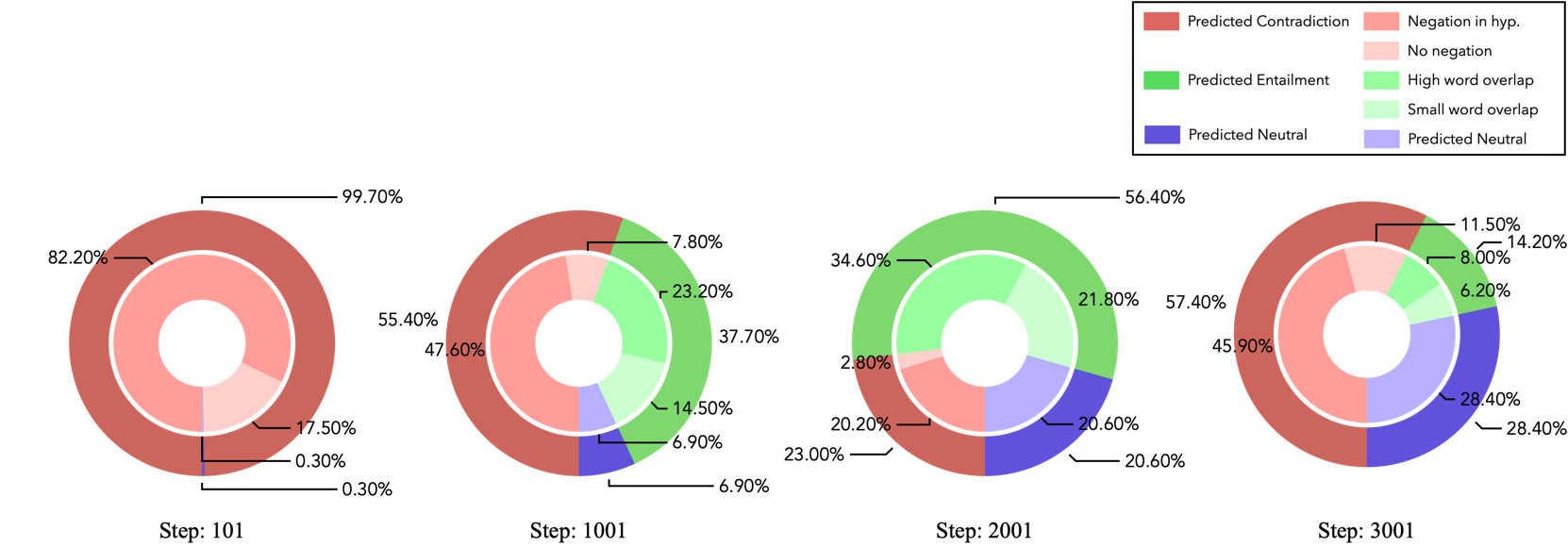
Composition of bias features in the misclassified group $G^\otimes$ on MultiNLI. After discovering Negation bias, Overlap bias gradually emerges.

GradCAM visualizations on MetaShift test data. ERM relies on background features, while ABD focuses on the target object.
BibTeX
@InProceedings{Bae_2024_ACCV,
author = {Bae, Jun-Hyun and Lee, Minho and Jung, Heechul},
title = {Adaptive Bias Discovery for Learning Debiased Classifier},
booktitle = {Proceedings of the Asian Conference on Computer Vision (ACCV)},
month = {December},
year = {2024},
pages = {3074-3090}
}