Jun-Hyun Bae, Inchul Choi, Minho Lee
Kyungpook National University
Abstract
Invariant Risk Minimization (IRM) aims to find predictors that generalize across out-of-distribution (OOD) environments by learning invariant correlations rather than spurious ones. We propose meta-IRM, a meta-learning based approach that instantiates the IRM objective using MAML. The key idea is assigning different training environments to the inner and outer optimization loops — since spurious correlations vary across environments, this naturally drives the model toward invariant features. We empirically evaluate meta-IRM on Colored MNIST variants including multi-class, insufficient data, and multiple spurious correlation settings.
Overview
We directly solve the ideal IRM bi-level optimization using the MAML framework, assigning different training environments to inner and outer loops to learn invariant features.
- Environment-specific adaptation — Adapt model parameters to each training environment \(e_i\) in the inner loop.
- Cross-environment evaluation — Evaluate the adapted parameters \(\theta_i'\) on a different environment \(e_j\) to compute the meta-loss.
- Invariant convergence — Combining gradients from different environments cancels spurious correlations, converging toward invariant features.
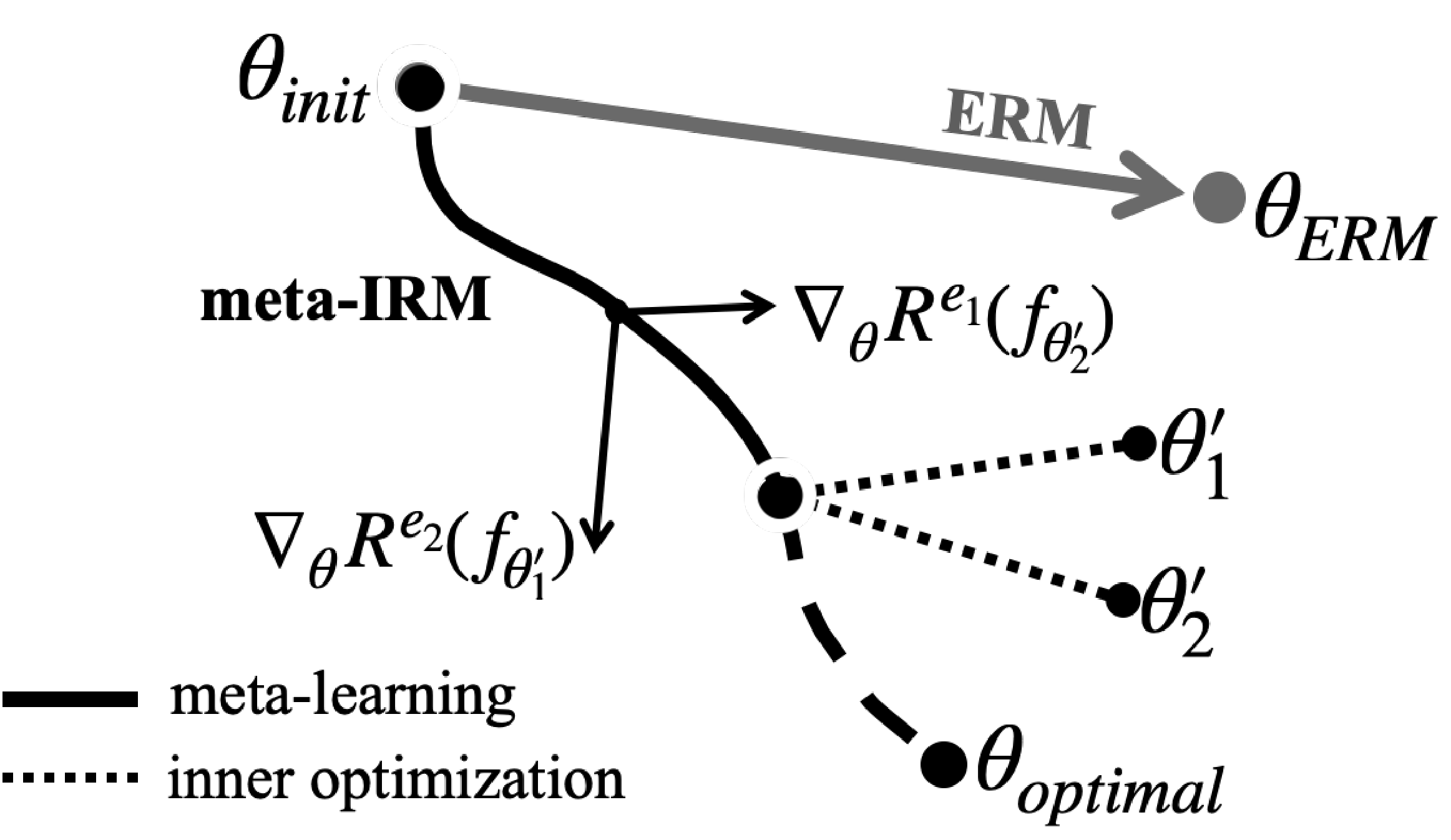
Diagram of meta-IRM. Gradients from environment-adapted parameters are combined to converge toward the invariant feature direction ($\theta_{optimal}$).
Method
IRM aims to find an invariant predictor across multiple training environments. Meta-IRM approaches this using the MAML framework, with a key insight: assigning different training environments to the inner loop and outer loop. Since spurious correlations vary across environments, combining gradients from different environments drives convergence toward invariant features.
Meta-Learning Framework
The inner/outer structure of MAML maps onto the IRM objective. The inner loop adapts to one environment, while the outer loop (meta-loss) evaluates on a different environment.
Inner optimization: Adapt model parameters to each training environment \(e_i\) :
\[\theta_i' = \theta - \alpha \nabla_\theta R^{e_i}(f_\theta)\]Meta-optimization: Update \(\theta\) using meta-losses computed from different environments \(e_j\) with adapted parameters \(\theta_i'\) :
\[\theta \leftarrow \theta - \beta \nabla_\theta \left\{ \sum_i \sum_j R^{e_j}(f_{\theta_i'}) + \lambda \sigma \right\}, \quad e_j \sim \mathcal{E}_{tr} \setminus e_i\]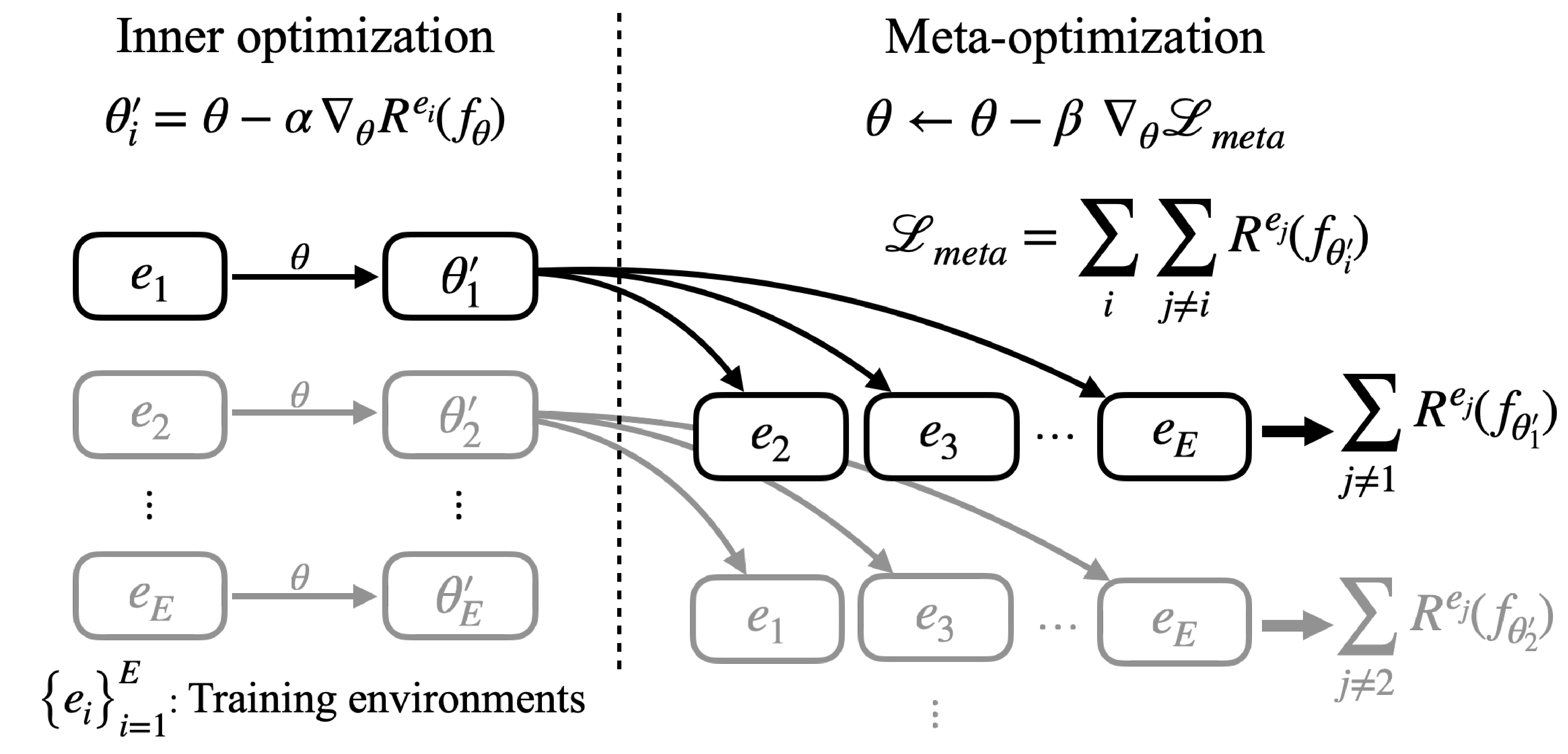
Schematic of meta-IRM learning process. Model parameters $\theta$ are adapted to training environments in the inner optimization; each adapted parameter computes meta-loss from different environments.
Auxiliary Standard Deviation Loss
An auxiliary loss based on the standard deviation \(\sigma\) of meta-losses encourages uniform performance across all environments. This regularization improves training stability and convergence speed.
Results
Colored MNIST
Test accuracy (%) on Colored MNIST. $p_e=0.9$ is the OOD environment (reversed color-label correlation).
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| ERM | 88.6 ± 0.3 | 79.7 ± 0.6 | 16.4 ± 0.8 |
| IRMv1 | 71.4 ± 0.9 | 70.8 ± 1.0 | 66.9 ± 2.5 |
| V-REx | 71.5 ± 0.8 | 71.1 ± 0.9 | 68.6 ± 1.2 |
| meta-IRM (Ours) | 70.9 ± 0.9 | 70.8 ± 1.0 | 70.4 ± 0.9 |
| Optimal | 75 | 75 | 75 |
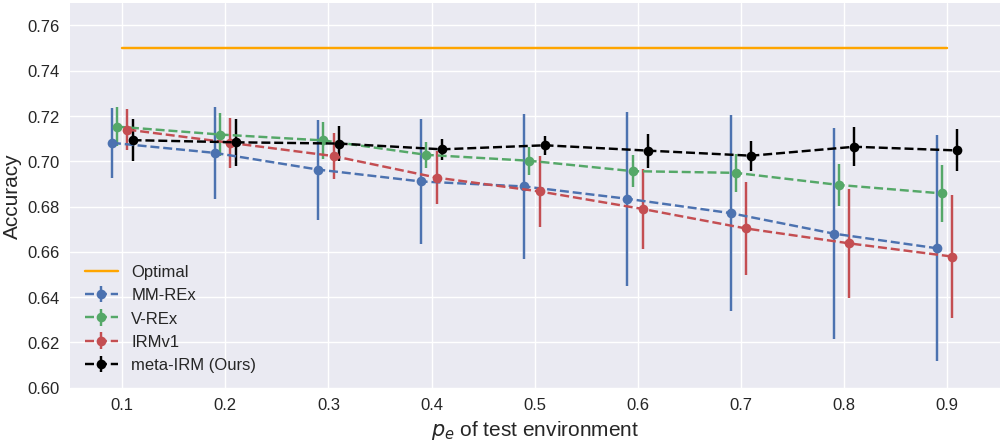
Accuracy across test environments ($p_e$ from 0.1 to 0.9).
Multi-Class Problem
Multi-class Colored MNIST ($k$=5, 10) test accuracy (%).
| Algorithm | # Classes | Train | Test (OOD) |
|---|---|---|---|
| ERM | 5 | 95.2 ± 0.2 | 41.0 ± 0.6 |
| IRMv1 | 5 | 82.2 ± 0.4 | 62.0 ± 2.4 |
| meta-IRM (Ours) | 5 | 76.4 ± 1.4 | 74.0 ± 3.6 |
| ERM | 10 | 92.6 ± 0.2 | 39.2 ± 0.9 |
| IRMv1 | 10 | 83.4 ± 0.5 | 58.6 ± 2.5 |
| meta-IRM (Ours) | 10 | 79.5 ± 0.6 | 73.4 ± 3.2 |
| Optimal | — | 75 | 75 |
Insufficient Data
Results when training data is halved (25,000 to 12,500 per environment).
Test accuracy (%) with reduced training data (12,500 per environment).
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 73.2 ± 1.6 | 71.7 ± 1.3 | 58.5 ± 2.5 |
| V-REx | 75.0 ± 0.8 | 73.4 ± 0.6 | 61.3 ± 1.4 |
| meta-IRM (Ours) | 70.6 ± 1.5 | 70.5 ± 1.6 | 68.3 ± 2.3 |
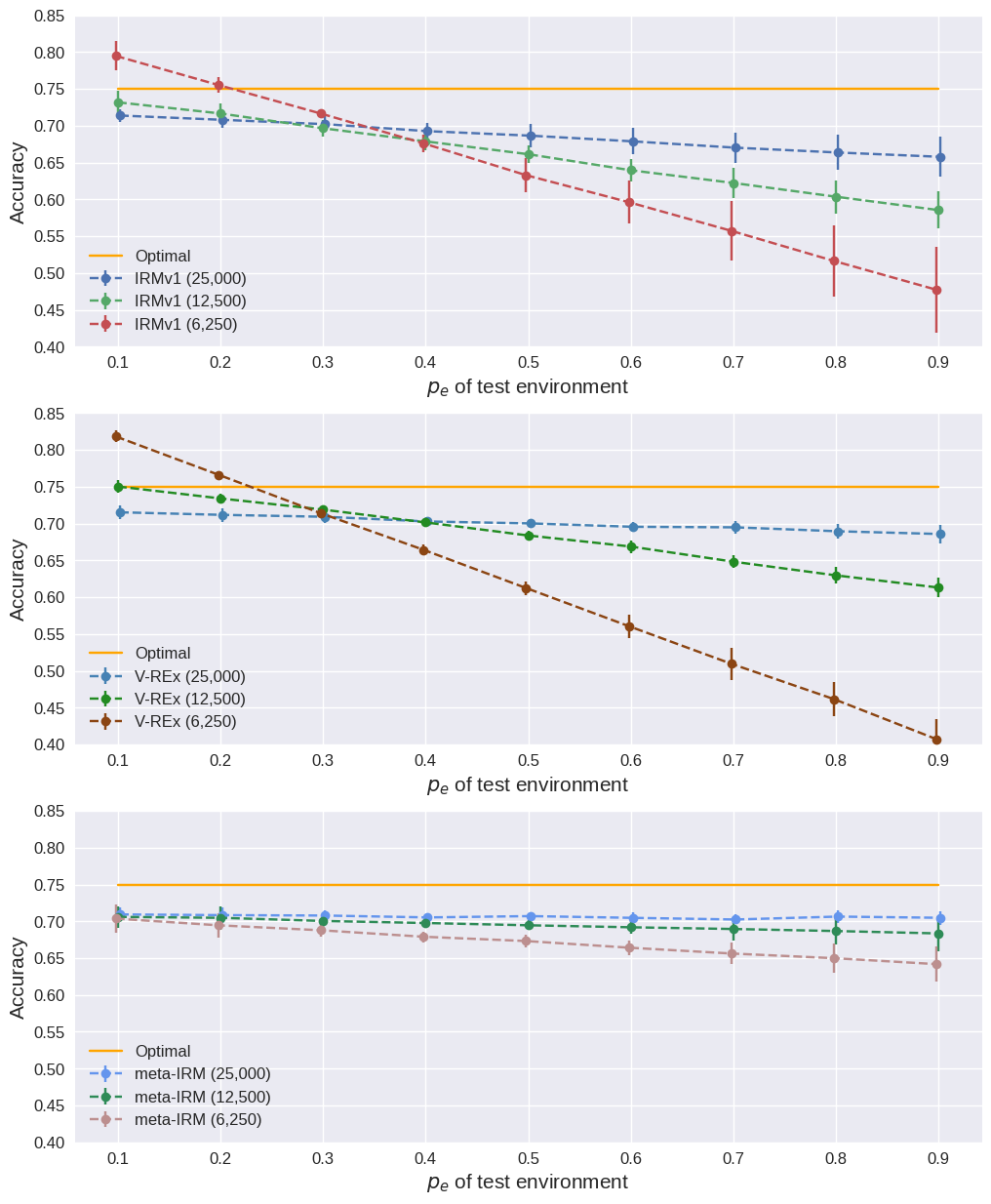
Effect of decreasing training data (25,000 → 12,500 → 6,250).
Two Spurious Features
Results with 2 spurious correlations (color + patch) and 2 training environments.
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 93.5 ± 0.2 | 86.4 ± 0.3 | 13.4 ± 0.3 |
| V-REx | 93.6 ± 0.4 | 86.3 ± 0.3 | 13.5 ± 0.3 |
| meta-IRM (Ours) | 58.1 ± 3.1 | 56.8 ± 2.9 | 54.5 ± 4.0 |
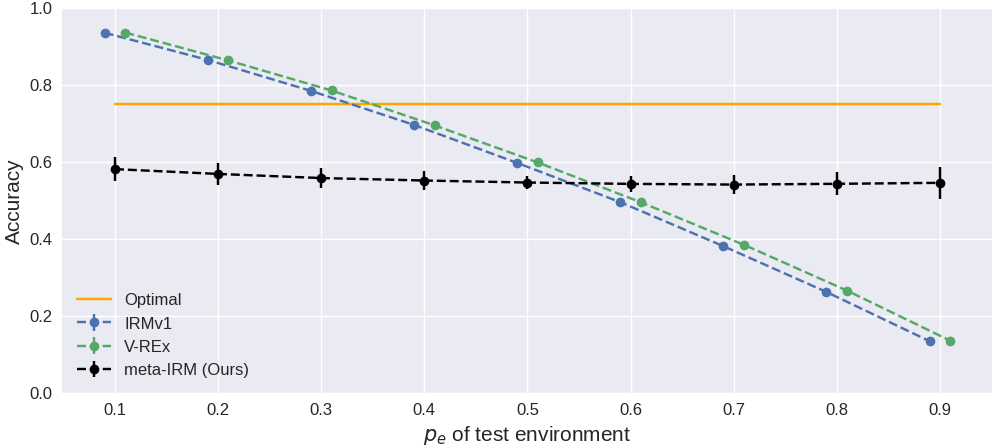
Test accuracy with two spurious features (color + patch) across environments.
Ablation Study
| Variant | \(p_e=0.1\) | \(p_e=0.9\) (OOD) |
|---|---|---|
| w/o std. loss | 73.0 ± 0.8 | 64.2 ± 3.2 |
| First-order approx. | 62.6 ± 5.5 | 59.1 ± 6.3 |
| Same env. (inner = meta) | 89.3 ± 1.6 | 13.6 ± 6.6 |
| meta-IRM (Full) | 70.9 ± 0.9 | 70.4 ± 0.9 |
BibTeX
@article{bae2021meta,
author = {Bae, Jun-Hyun and Choi, Inchul and Lee, Minho},
title = {Meta-Learned Invariant Risk Minimization},
journal = {arXiv preprint arXiv:2103.12947},
year = {2021}
}