Jaesin Ahn, Chaehyeon Lee, Jun-Hyun Bae, Junho Yim, Heechul Jung
Kyungpook National University · LG Energy Solution
8th place out of 1,188 teams
Abstract
Machine unlearning addresses the problem of removing the influence of specific training data from a trained model. While retraining from scratch is ideal, it is prohibitively expensive. This technical report introduces methods validated in the NeurIPS 2023 Machine Unlearning Challenge: stochastic re-initialization, knowledge preserving loss, gaussian noise augmentation, and forget-remember cycles. Our approach achieves high unlearning performance using only the retain set, without accessing the forget set.
Overview
We propose a machine unlearning method that effectively removes the influence of specific data using only the retain set, without accessing the forget set or retraining from scratch.
- Stochastic re-initialization — Randomly select and re-initialize model layers to probabilistically destroy memories of specific data.
- Knowledge preserving — Reproduce the original model’s outputs on the retain set via MSE loss to maintain performance.
- Forget-remember cycles — Repeat forgetting and remembering phases 3-4 times, progressively increasing re-initialization ratio while preserving retain set performance.
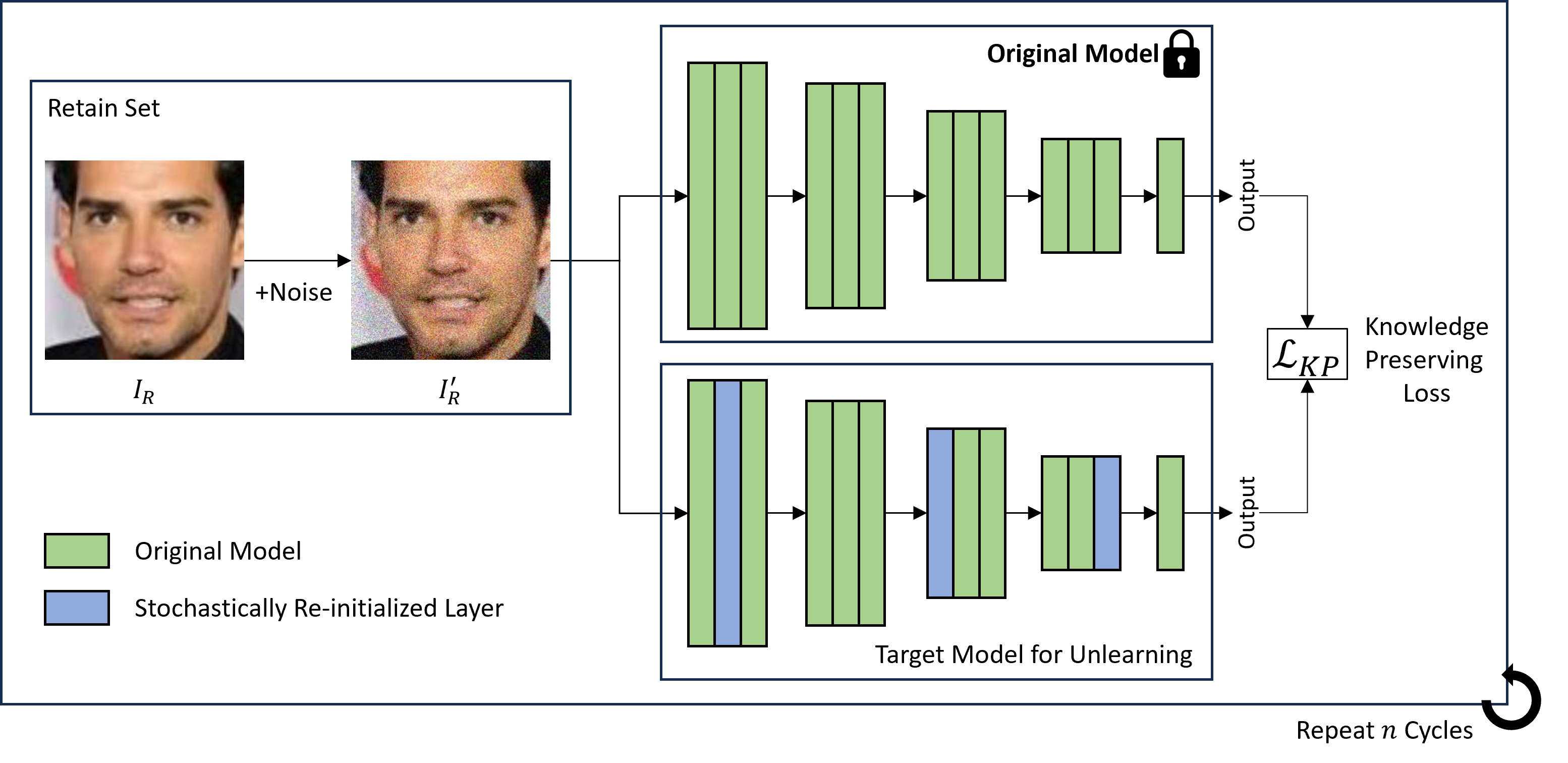
Overall architecture. (a) Gaussian noise added to retain set images, (b) random layers selected for stochastic re-initialization, (c) knowledge preserving loss computed between original and unlearning models, (d) steps (a)-(c) repeated for $n$ cycles.
Method
The overall pipeline repeats forgetting phases and remembering phases in a cycle structure.
Stochastic Re-initialization
We randomly select and re-initialize a subset of model layers, then fine-tune on the retain set. Random selection outperformed Fisher information matrix (FIM)-based selection because the competition metric evaluates distributions across 512 independent runs, requiring sufficient randomness.
FC layers and projection-shortcut layers are excluded from the selection pool as they encode class/resolution information unrelated to specific data points.
Knowledge Preserving Loss
By definition, an unlearned model should behave similarly to a retrained model. We train the model to reproduce the original model’s outputs on the retain set via MSE loss:
\[\mathcal{L}_{KP} = \mathbb{E}\left[|f_O(\mathbf{I}'_R) - f_U(\mathbf{I}'_R)|^2\right]\]Gaussian Noise Augmentation
Adding gaussian noise (\(\sigma=0.01\) ) to retain set images provides sufficient randomness while achieving robust knowledge preservation.
Forget-Remember Cycles
Simply increasing the re-initialization ratio causes excessive forgetting. Instead, repeating 3-4 cycles of forgetting and remembering phases progressively increases the effective re-initialization ratio while maintaining retain set performance.
Results
Quantitative
| Model | Score |
|---|---|
| Negrad | 0.0001 (±0.0001) |
| Fine-tune (baseline) | 0.0464 (±0.0031) |
| Ours | 0.0935 (±0.0060) |
| Ours (best) | 0.1024 |
| Experiment | Score |
|---|---|
| Fine-tune only | 0.0496 |
| + Stochastic Re-init (random) | 0.0617 |
| + FIM-based Re-init | 0.0486 |
| + Gaussian Noise | 0.0653 |
| + MSE Loss (vs CE) | 0.0680 |
| + 3 Cycles | 0.0856 |
| + Exclude FC/shortcut | 0.0969 |
Qualitative
Comparing logit distributions on the forget set and retain set, our method produces distributions much closer to the retrained model than fine-tuning.
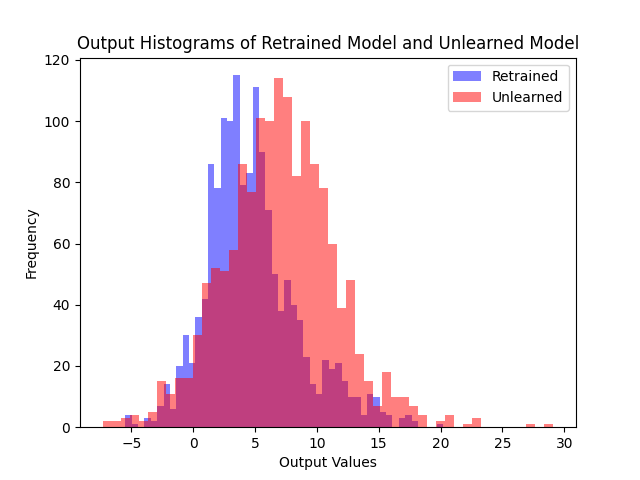
(a) Fine-tune
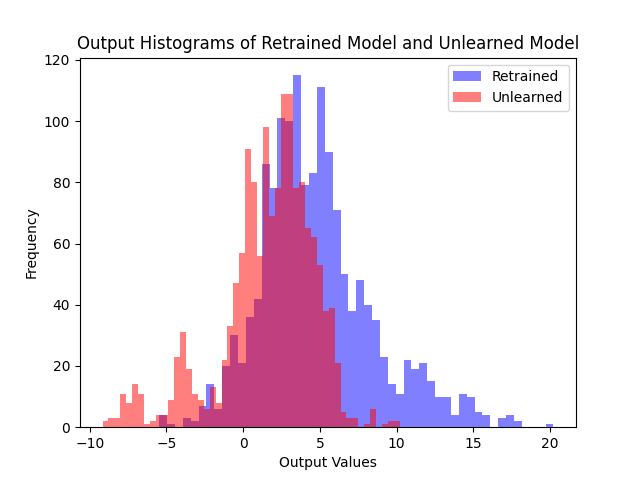
(b) Ours
Logit distributions on the forget set. Our method produces distributions much closer to the retrained model compared to fine-tuning.
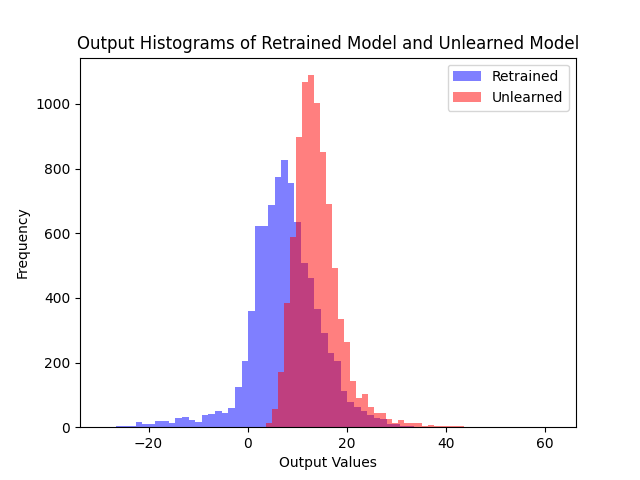
(a) Fine-tune
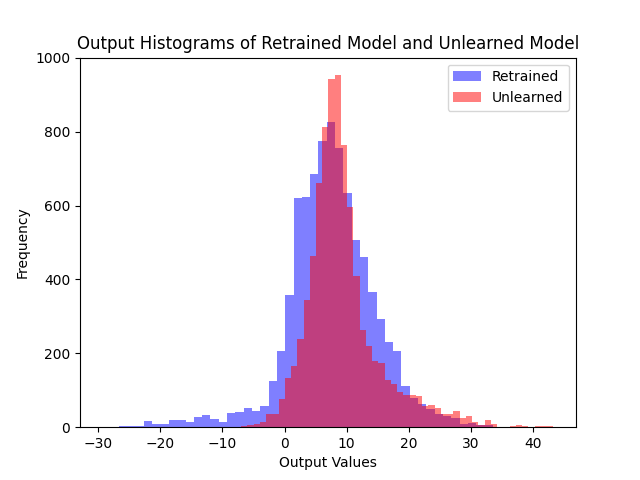
(b) Ours
Logit distributions on the retain set. Our method maintains similar outputs to the retrained model on the retain set.
BibTeX
@misc{ahn2023stochastic,
author = {Ahn, Jaesin and Lee, Chaehyeon and Bae, Jun-Hyun
and Yim, Junho and Jung, Heechul},
title = {Stochastic Unlearning with Knowledge Preserving Loss},
year = {2023},
note = {NeurIPS 2023 Machine Unlearning Challenge,
8th place out of 1,188 teams},
url = {https://www.kaggle.com/competitions/neurips-2023-machine-unlearning/writeups/forget-9th-place-solution-forget-set-free-approach}
}