Jun-Hyun Bae, Minho Lee, Heechul Jung
Kyungpook National University
Abstract
Training deep neural networks with empirical risk minimization (ERM) often captures dataset biases, hindering generalization to new or unseen data. Previous solutions either require prior knowledge of biases or utilize training intentionally biased models as auxiliaries; however, they still suffer from multiple biases. To address this, we introduce Adaptive Bias Discovery (ABD), a novel learning framework designed to mitigate the impact of multiple unknown biases. ABD trains an auxiliary model to be adapted to biases based on the debiased parameters from the debiasing phase, allowing it to navigate through multiple biases. Then, samples are reweighted based on the discovered biases to update debiased parameters. Extensive evaluations of synthetic experiments and real-world datasets demonstrate that ABD consistently outperforms existing methods, particularly in real-world applications where multiple unknown biases are prevalent.
Overview
사전 바이어스 정보 없이 데이터에 존재하는 여러 바이어스를 순차적으로 발견하고 제거하는 학습 프레임워크를 제안한다.
- Bias-adapted model — Debiased 파라미터 \(\theta\) 에서 1-step gradient descent로 바이어스에 민감한 보조 모델 \(f_\phi\) 를 생성한다.
- Adaptive group formation — \(f_\phi\) 의 예측으로 데이터를 바이어스 정렬 그룹(\(G^\odot\) )과 비정렬 그룹(\(G^\otimes\) )으로 분할한다.
- Iterative debiasing — Group DRO로 worst-case 그룹 손실을 최소화하며, \(\theta\) 가 한 바이어스에 강건해지면 \(\phi\) 가 자연스럽게 다음 바이어스를 발견한다.
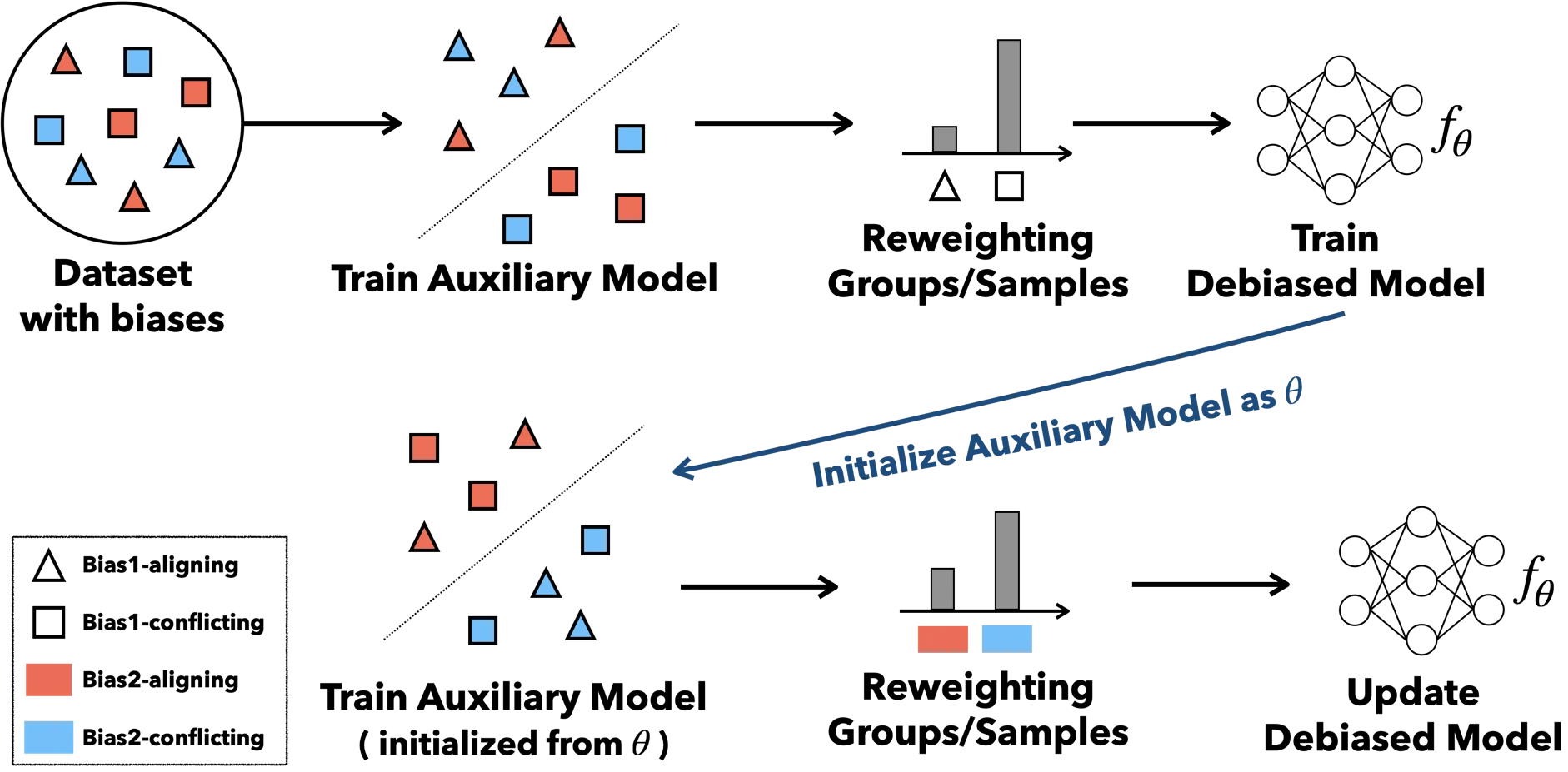
ABD 프레임워크 개요. 두 가지 바이어스(Bias1, Bias2)와 두 학습 스텝을 예시로 도식화.
Method
ERM으로 학습된 모델은 데이터에 존재하는 spurious correlation을 쉽게 포착하여 일반화 성능이 저하된다. 기존 방법들은 바이어스 정보를 사전에 알고 있어야 하거나(Group DRO), 단일 바이어스만 처리할 수 있다는(PI, JTT) 한계가 있다.
ABD는 두 단계로 구성된다. 먼저 debiased 파라미터 \(\theta\) 에서 한 스텝 gradient descent로 bias-adapted 파라미터 \(\phi = \theta - \alpha \nabla_\theta \mathcal{L}(f_\theta)\) 를 얻는다. 이 \(f_\phi\) 는 데이터의 표면적 패턴에 민감하게 반응하므로, 예측 결과를 기반으로 데이터를 바이어스 정렬 그룹(\(G^\odot\) )과 비정렬 그룹(\(G^\otimes\) )으로 분할한다. 이후 group DRO를 통해 worst-case 그룹의 손실을 최소화하도록 \(\theta\) 를 업데이트한다.
핵심은 \(\phi\) 가 매 스텝마다 \(\theta\) 로부터 재생성된다는 점이다. \(\theta\) 가 첫 번째 바이어스에 대해 강건해지면, \(\phi\) 가 다음으로 두드러진 바이어스를 포착하게 된다. 이 MAML 유사 구조 덕분에 사전 바이어스 정보 없이도 여러 바이어스를 순차적으로 발견하고 제거할 수 있다.
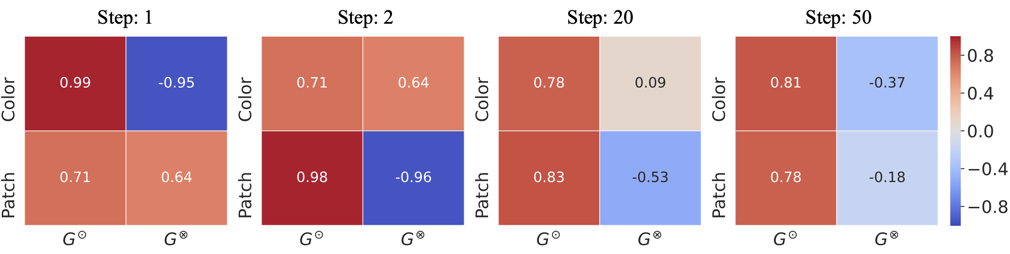
아래 GradCAM 시각화는 biased model \(f_\phi\) 의 attention이 학습이 진행됨에 따라 다른 영역으로 이동하는 것을 보여준다. 이는 ABD가 학습 과정에서 다양한 바이어스를 적응적으로 발견함을 시각적으로 확인할 수 있는 증거이다.

ERM 모델과 ABD의 biased model $f_\phi$의 GradCAM 시각화. 학습 스텝이 진행되면서 $f_\phi$의 attention이 다른 바이어스 특징으로 이동한다.
Results
Colored MNIST — 복수 바이어스 처리
기존 방법과의 차이를 가장 잘 보여주는 실험이다. 바이어스가 Color 하나일 때와 Color + Patch 둘 다 존재할 때를 비교한다.
OoD test accuracy (%). 바이어스가 하나일 때와 둘 다 존재할 때의 비교.
| Algorithm | Color (OoD) | Color & Patch (OoD) |
|---|---|---|
| ERM | 16.4 | 14.0 |
| IRM | 66.9 | 13.4 |
| Group DRO | 13.6 | 14.1 |
| PI | 70.2 | 15.3 |
| ABD (Ours) | 70.7 | 62.3 |
| Optimal | 75.0 | 75.0 |
PI는 Color 바이어스만 발견하고 Patch는 포착하지 못하여, 바이어스가 두 개가 되면 15.3%로 사실상 실패한다 (54.9%p 하락). IRM과 Group DRO 역시 복수 바이어스 환경에서 ERM 수준에 머문다. ABD는 Color → Patch 순으로 바이어스를 순차적으로 발견하여, 복수 바이어스 환경에서 유의미한 OoD 성능(62.3%)을 달성하는 유일한 방법이다.
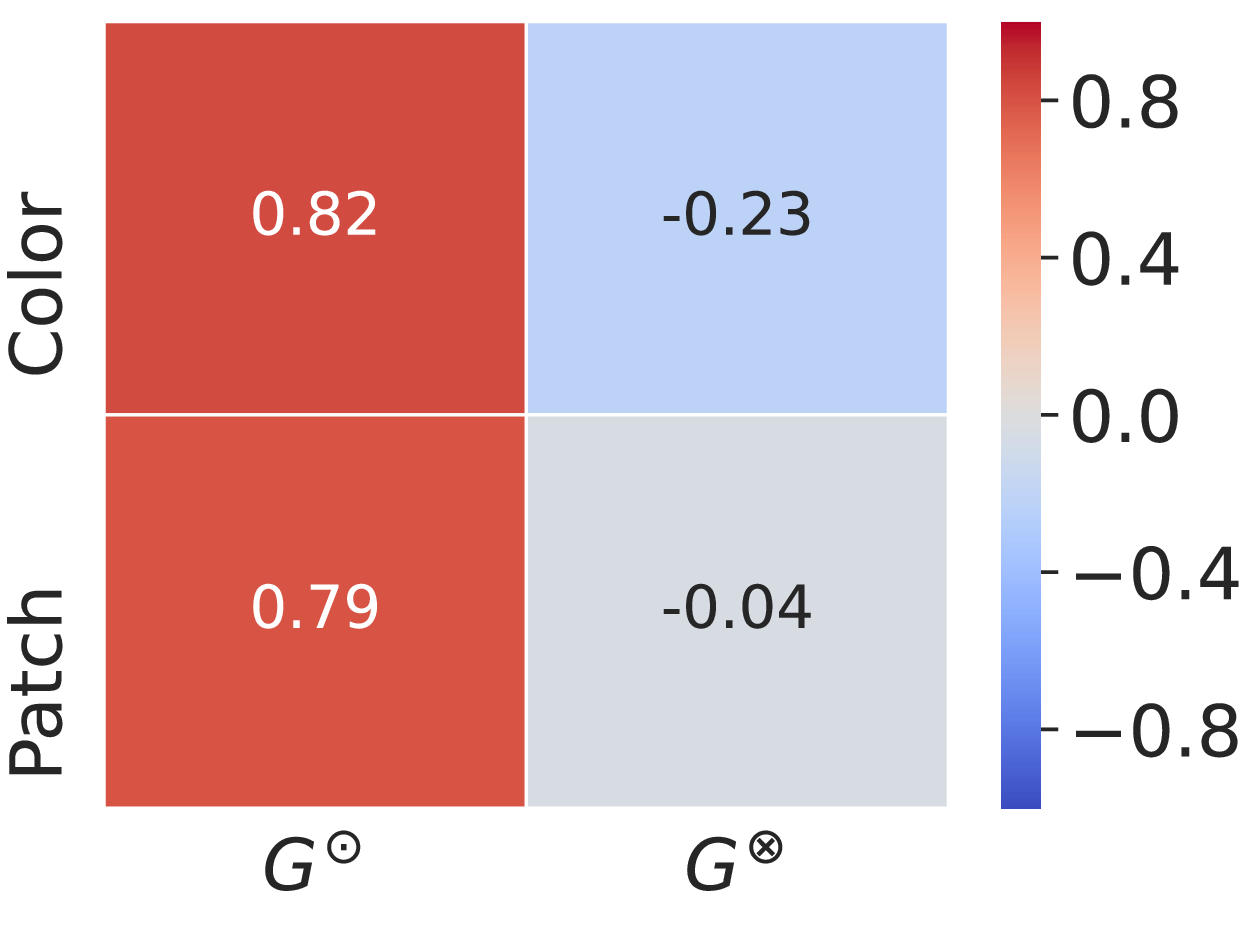
그룹 내 Pearson 상관계수 비교.
Real-World Tasks
바이어스 annotation이 있는 데이터셋 — CivilComments & MultiNLI
Worst-case test accuracy (%). CivilComments의 Group 열은 각 알고리즘이 그룹화에 사용한 demographic 정보를, MultiNLI의 Group DRO*는 prior bias 정보로 수작업 정의된 그룹을 사용한 oracle 설정이다.
| Algorithm | CivilComments | Group (CC) | MultiNLI |
|---|---|---|---|
| ERM | 56.0 | None | 61.8 |
| IRM | 66.3 | (label × Black) | — |
| Group DRO | 69.1 | (label) | 62.7 |
| Group DRO | 70.0 | (label × Black) | — |
| JTT | 69.3 | None | 63.2 |
| PI | 61.1 | None | 61.5 |
| ABD (Ours) | 71.1 | None | 67.1 |
| Group DRO* (oracle) | — | — | 67.5 |
바이어스 annotation이 없는 데이터셋 — Camelyon17 & FMoW (WILDS)
Camelyon17-wilds는 OoD average accuracy, FMoW-wilds는 worst-region accuracy (%).
| Algorithm | Camelyon17 | FMoW |
|---|---|---|
| ERM | 70.3 ± 6.4 | 32.3 ± 1.3 |
| IRM | 59.5 ± 7.7 | 31.7 ± 1.2 |
| Group DRO | 68.4 ± 7.3 | 30.8 ± 0.8 |
| CORAL | 59.5 ± 7.7 | 32.8 ± 0.7 |
| JTT | 63.8 ± 1.4 | 33.4 ± 0.9 |
| PI | 71.7 ± 7.5 | 31.2 ± 0.3 |
| CGD | 69.4 ± 7.9 | 32.0 ± 2.3 |
| LISA | 77.1 ± 6.5 | 35.5 ± 0.7 |
| ABD (Ours) | 81.1 ± 4.8 | 34.1 ± 2.5 |
CivilComments에서 ABD(71.1%)는 바이어스 annotation을 사용하는 Group DRO(label × Black, 70.0%)를 annotation 없이 능가한다. MultiNLI에서는 ABD(67.1%)가 수작업 그룹을 사용하는 oracle Group DRO*(67.5%)에 0.4%p 이내로 근접하며, 사전 바이어스 정보 없이 이에 필적하는 성능을 달성한다. Camelyon17에서는 LISA 대비 +4.0%p 향상(81.1% vs 77.1%)을 보이며, FMoW에서도 LISA에 근접한 경쟁력 있는 성능을 유지한다. IRM, CORAL, CGD 등 distribution alignment 또는 invariance 기반 접근은 WILDS 벤치마크에서 ERM 수준에 머물거나 오히려 하락한다.
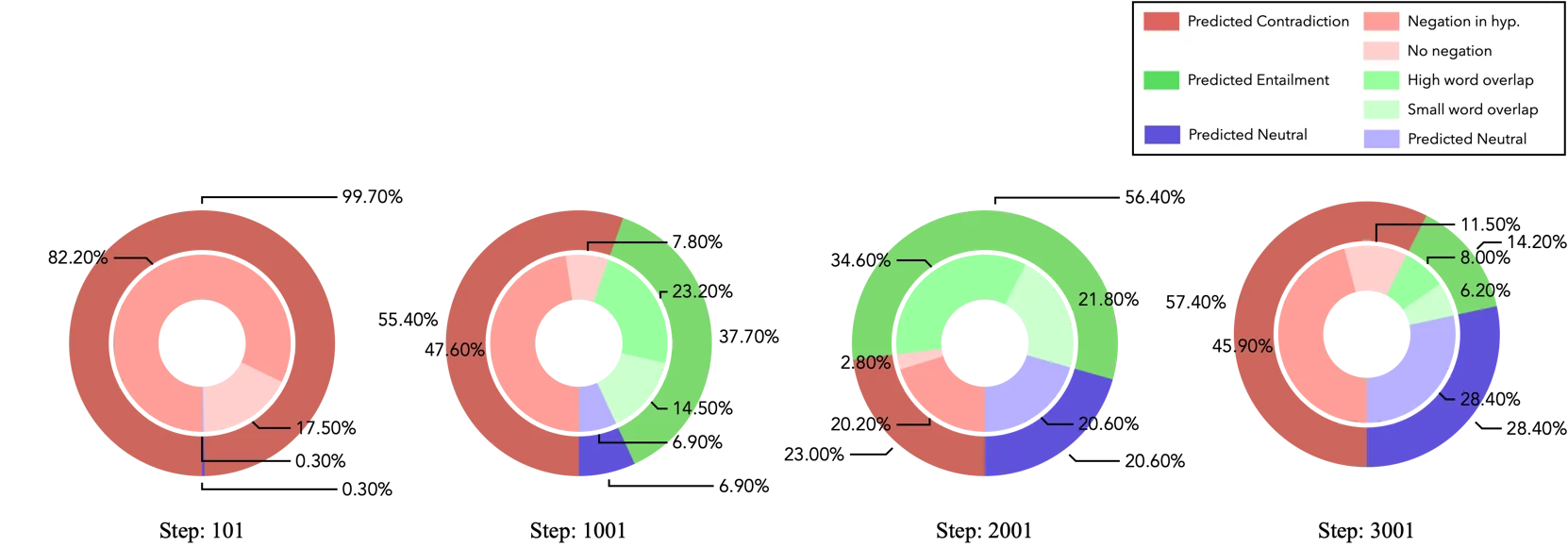
MultiNLI에서 오분류 그룹 $G^\otimes$의 바이어스 구성 변화. Negation 바이어스 발견 후 Overlap 바이어스가 점차 드러난다.
MetaShift — Distributional Distance에 따른 성능 변화
MetaShift에서는 training과 test 간 distributional distance를 조절하여 각 방법의 강건성을 평가한다. ABD의 우위는 distributional distance가 커질수록 더욱 두드러진다.
MetaShift test accuracy (%). Distance가 클수록 분포 차이가 크다.
| Distance | 0.44 | 0.71 | 1.12 | 1.43 |
|---|---|---|---|---|
| ERM | 80.1 | 68.4 | 52.1 | 33.2 |
| IRM | 79.5 | 67.4 | 51.8 | 32.0 |
| Group DRO | 77.0 | 68.9 | 51.9 | 34.2 |
| LISA | 81.3 | 69.7 | 54.2 | 37.5 |
| ABD (Ours) | 80.4 | 71.8 | 55.2 | 41.8 |
Distance가 가장 작은 0.44에서는 LISA(81.3%)가 근소하게 앞서지만, distance가 커질수록 ABD의 우위가 뚜렷해져 1.43에서는 ABD(41.8%)가 LISA(37.5%)를 4.3%p 상회한다. 이는 ABD가 분포 차이가 클수록 효과적인, 실제 OoD 환경에 적합한 방법임을 보여준다.

MetaShift 테스트 데이터의 GradCAM 시각화. ERM은 배경에 의존하지만, ABD는 대상 객체에 집중한다.