Jun-Hyun Bae, Inchul Choi, Minho Lee
Kyungpook National University
Abstract
Invariant Risk Minimization (IRM) aims to find predictors that generalize across out-of-distribution (OOD) environments by learning invariant correlations rather than spurious ones. We propose meta-IRM, a meta-learning based approach that instantiates the IRM objective using MAML. The key idea is assigning different training environments to the inner and outer optimization loops — since spurious correlations vary across environments, this naturally drives the model toward invariant features. We empirically evaluate meta-IRM on Colored MNIST variants including multi-class, insufficient data, and multiple spurious correlation settings.
Overview
IRM의 이상적인 bi-level 최적화를 MAML 프레임워크로 직접 수행하며, 서로 다른 environment를 inner/outer loop에 배정하여 invariant feature를 학습한다.
- Environment-specific adaptation — 각 training environment \(e_i\) 에 대해 inner loop에서 모델 파라미터를 적응시킨다.
- Cross-environment evaluation — 적응된 파라미터 \(\theta_i'\) 를 다른 environment \(e_j\) 에서 평가하여 meta-loss를 계산한다.
- Invariant convergence — 서로 다른 environment의 gradient를 결합하면 spurious correlation은 상쇄되고, invariant feature 방향으로 수렴한다.
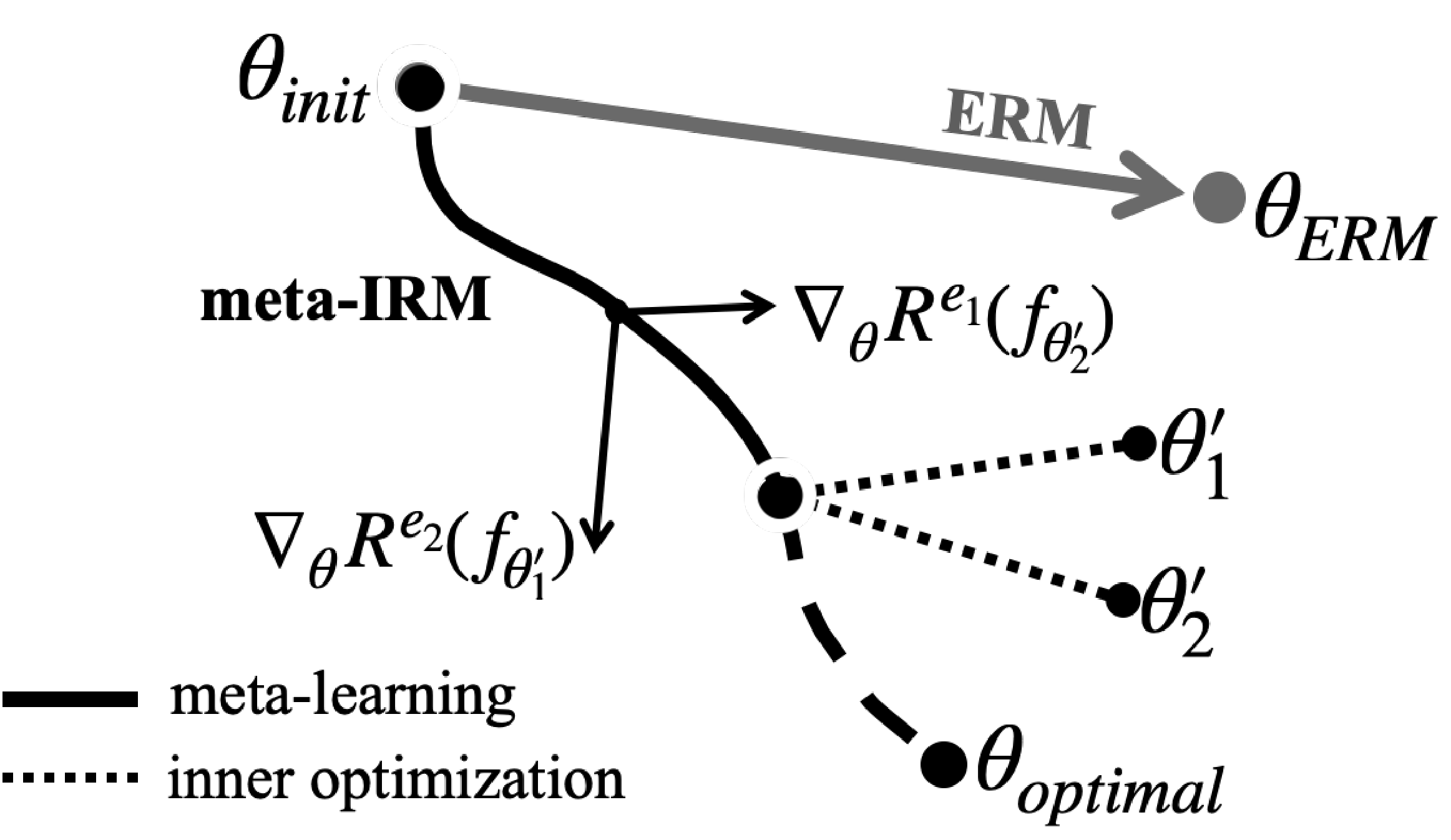
Meta-IRM의 학습 다이어그램. 각 environment에 adapted된 gradient를 결합하여 invariant feature 방향($\theta_{optimal}$)으로 수렴한다.
Method
IRM은 여러 training environment에 걸쳐 invariant한 predictor를 찾는 것이 목표다. Meta-IRM은 이를 MAML 프레임워크로 접근하며, 핵심 착안점은 inner loop와 outer loop에 서로 다른 training environment를 배정하는 것이다. Environment마다 spurious correlation의 방향이 다르므로, 서로 다른 environment에서 얻은 gradient를 결합하면 invariant feature 방향으로 수렴할 수 있다.
Meta-Learning Framework
MAML의 inner/outer 구조를 IRM에 대응시킨다. Inner loop에서는 한 environment에 적응하고, outer loop(meta-loss)에서는 다른 environment로 평가한다.
Inner optimization: 각 training environment \(e_i\) 에 대해 모델 파라미터를 적응시킨다:
\[\theta_i' = \theta - \alpha \nabla_\theta R^{e_i}(f_\theta)\]Meta-optimization: 적응된 파라미터 \(\theta_i'\) 로 다른 environment \(e_j\) 에서의 meta-loss를 계산하여 \(\theta\) 를 업데이트한다:
\[\theta \leftarrow \theta - \beta \nabla_\theta \left\{ \sum_i \sum_j R^{e_j}(f_{\theta_i'}) + \lambda \sigma \right\}, \quad e_j \sim \mathcal{E}_{tr} \setminus e_i\]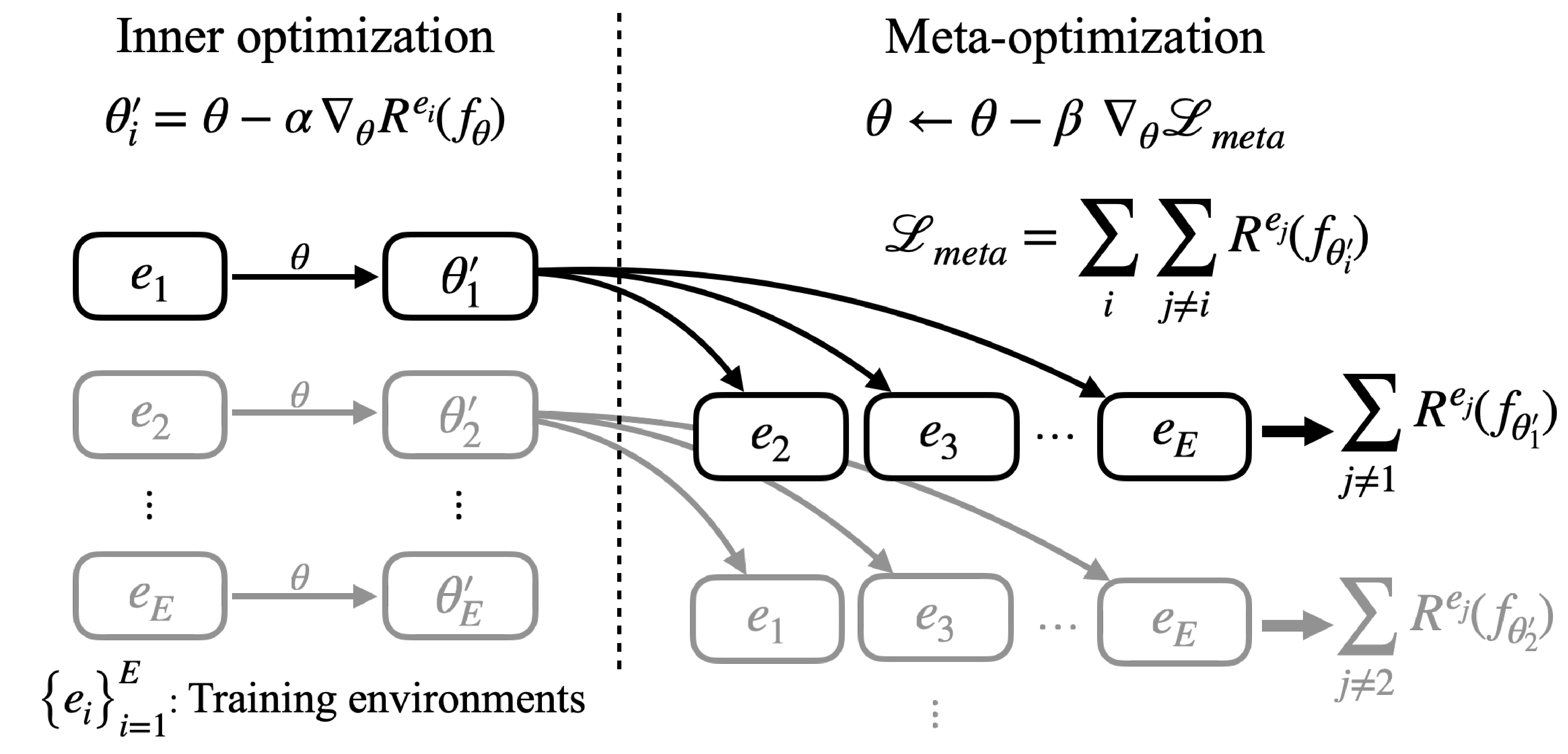
Meta-IRM 학습 과정. 모델 파라미터 $\theta$가 inner optimization에서 각 training environment에 적응되고, 적응된 파라미터로 다른 environment에서 meta-loss를 계산한다.
Auxiliary Standard Deviation Loss
Meta-loss의 표준편차 \(\sigma\) 를 보조 손실로 추가하여, 모든 environment에서 균일한 성능을 달성하도록 유도한다. 이 정규화는 학습 안정성을 높이고 수렴 속도를 개선한다.
Results
Colored MNIST
Test accuracy (%) on Colored MNIST. $p_e=0.9$이 OOD 환경 (color-label 상관관계 역전).
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| ERM | 88.6 ± 0.3 | 79.7 ± 0.6 | 16.4 ± 0.8 |
| IRMv1 | 71.4 ± 0.9 | 70.8 ± 1.0 | 66.9 ± 2.5 |
| V-REx | 71.5 ± 0.8 | 71.1 ± 0.9 | 68.6 ± 1.2 |
| meta-IRM (Ours) | 70.9 ± 0.9 | 70.8 ± 1.0 | 70.4 ± 0.9 |
| Optimal | 75 | 75 | 75 |
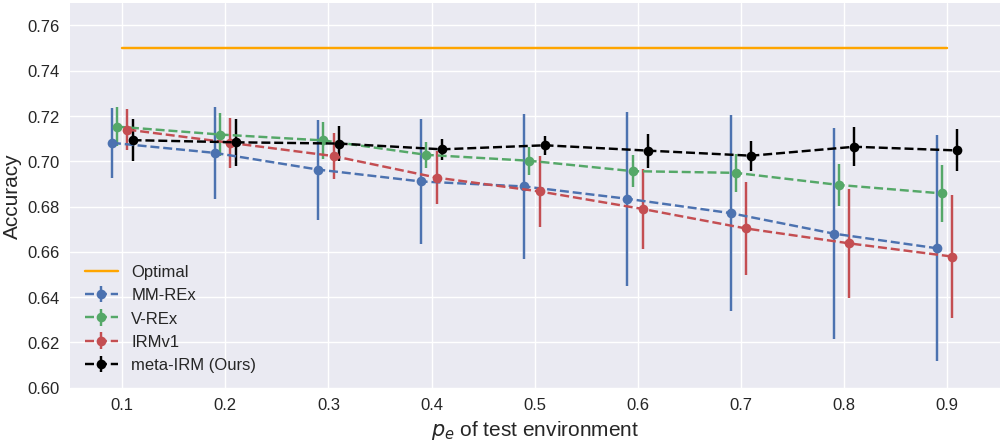
다양한 test environment ($p_e$ 0.1~0.9)에서의 정확도.
Multi-Class Problem
Multi-class Colored MNIST ($k$=5, 10) test accuracy (%).
| Algorithm | # Classes | Train | Test (OOD) |
|---|---|---|---|
| ERM | 5 | 95.2 ± 0.2 | 41.0 ± 0.6 |
| IRMv1 | 5 | 82.2 ± 0.4 | 62.0 ± 2.4 |
| meta-IRM (Ours) | 5 | 76.4 ± 1.4 | 74.0 ± 3.6 |
| ERM | 10 | 92.6 ± 0.2 | 39.2 ± 0.9 |
| IRMv1 | 10 | 83.4 ± 0.5 | 58.6 ± 2.5 |
| meta-IRM (Ours) | 10 | 79.5 ± 0.6 | 73.4 ± 3.2 |
| Optimal | — | 75 | 75 |
Insufficient Data
Training data가 절반(12,500)으로 줄었을 때의 결과.
Training data 감소 시 test accuracy (%). 25,000 → 12,500 per environment.
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 73.2 ± 1.6 | 71.7 ± 1.3 | 58.5 ± 2.5 |
| V-REx | 75.0 ± 0.8 | 73.4 ± 0.6 | 61.3 ± 1.4 |
| meta-IRM (Ours) | 70.6 ± 1.5 | 70.5 ± 1.6 | 68.3 ± 2.3 |
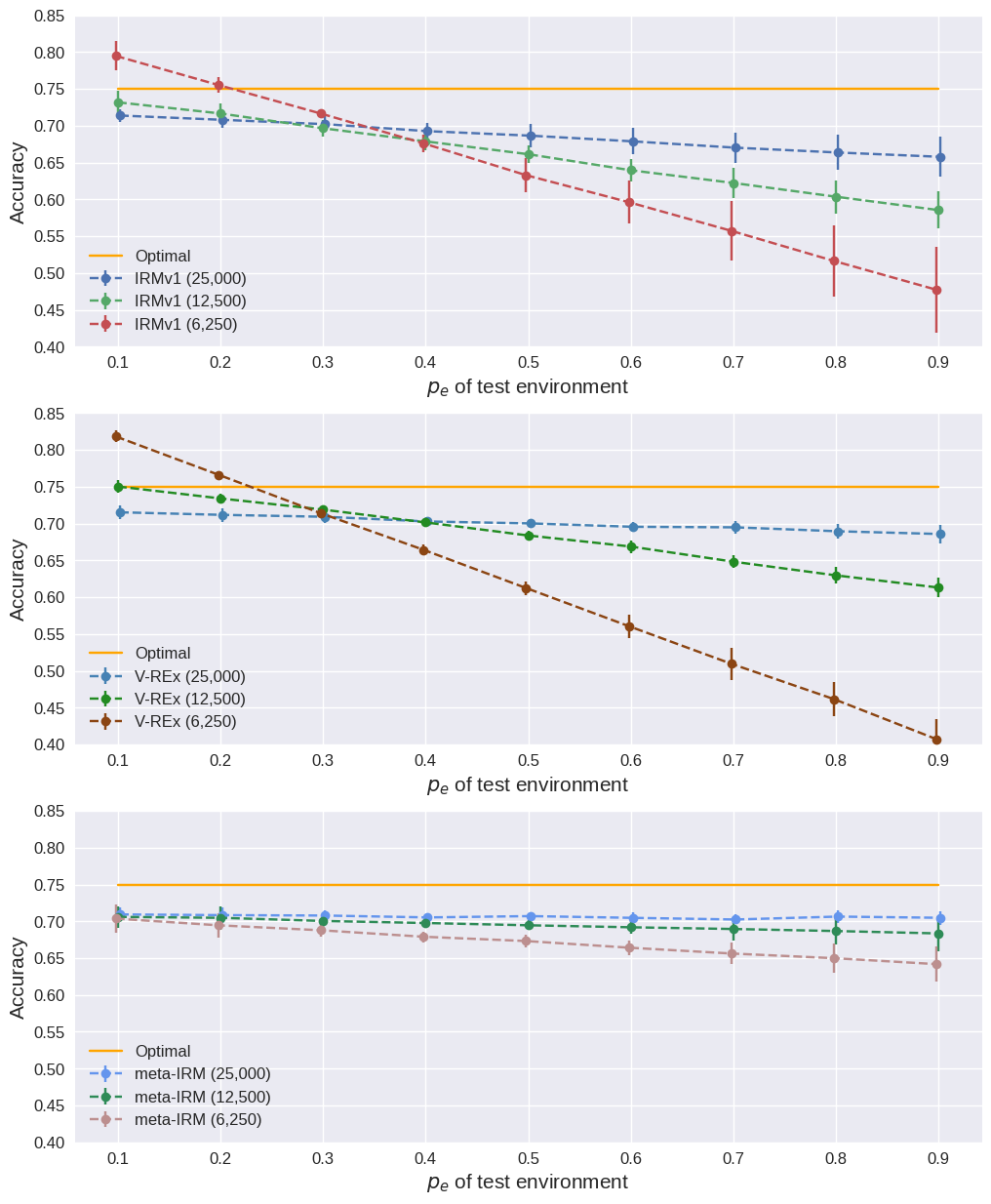
Training data 감소에 따른 영향 (25,000 → 12,500 → 6,250).
Two Spurious Features
Spurious correlation이 2개(color + patch)이고 environment가 2개인 경우.
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 93.5 ± 0.2 | 86.4 ± 0.3 | 13.4 ± 0.3 |
| V-REx | 93.6 ± 0.4 | 86.3 ± 0.3 | 13.5 ± 0.3 |
| meta-IRM (Ours) | 58.1 ± 3.1 | 56.8 ± 2.9 | 54.5 ± 4.0 |
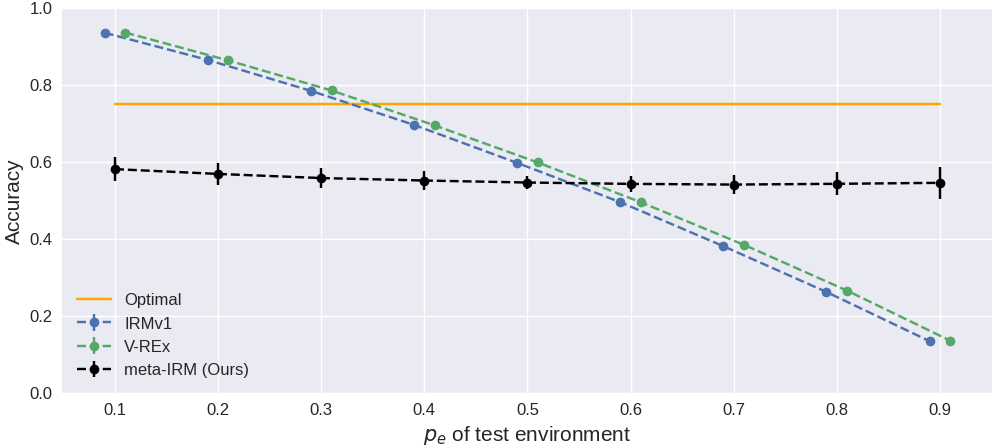
두 가지 spurious feature (color + patch) 존재 시 각 알고리즘의 test environment별 정확도.
Ablation Study
| Variant | \(p_e=0.1\) | \(p_e=0.9\) (OOD) |
|---|---|---|
| w/o std. loss | 73.0 ± 0.8 | 64.2 ± 3.2 |
| First-order approx. | 62.6 ± 5.5 | 59.1 ± 6.3 |
| Same env. (inner = meta) | 89.3 ± 1.6 | 13.6 ± 6.6 |
| meta-IRM (Full) | 70.9 ± 0.9 | 70.4 ± 0.9 |
BibTeX
@article{bae2021meta,
author = {Bae, Jun-Hyun and Choi, Inchul and Lee, Minho},
title = {Meta-Learned Invariant Risk Minimization},
journal = {arXiv preprint arXiv:2103.12947},
year = {2021}
}