Jun-Hyun Bae, Inchul Choi, Minho Lee
Kyungpook National University
Abstract
Empirical Risk Minimization (ERM) based machine learning algorithms have suffered from weak generalization performance on data obtained from out-of-distribution (OOD). To address this problem, Invariant Risk Minimization (IRM) objective was suggested to find invariant optimal predictor which is less affected by the changes in data distribution. However, even with such progress, IRMv1, the practical formulation of IRM, still shows performance degradation when there are not enough training data, and even fails to generalize to OOD, if the number of spurious correlations is larger than the number of environments. In this paper, to address such problems, we propose a novel meta-learning based approach for IRM. In this method, we do not assume the linearity of classifier for the ease of optimization, and solve ideal bi-level IRM objective with Model-Agnostic Meta-Learning (MAML) framework. Our method is more robust to the data with spurious correlations and can provide an invariant optimal classifier even when data from each distribution are scarce. In experiments, we demonstrate that our algorithm not only has better OOD generalization performance than IRMv1 and all IRM variants, but also addresses the weakness of IRMv1 with improved stability.
Overview
IRM의 이상적인 bi-level 최적화를 MAML 프레임워크로 직접 수행하며, 서로 다른 environment를 inner/outer loop에 배정하여 invariant feature를 학습한다.
- Environment-specific adaptation — 각 training environment \(e_i\) 에 대해 inner loop에서 모델 파라미터를 적응시킨다.
- Cross-environment evaluation — 적응된 파라미터 \(\theta_i'\) 를 다른 environment \(e_j\) 에서 평가하여 meta-loss를 계산한다.
- Invariant convergence — 서로 다른 environment의 gradient를 결합하면 spurious correlation은 상쇄되고, invariant feature 방향으로 수렴한다.
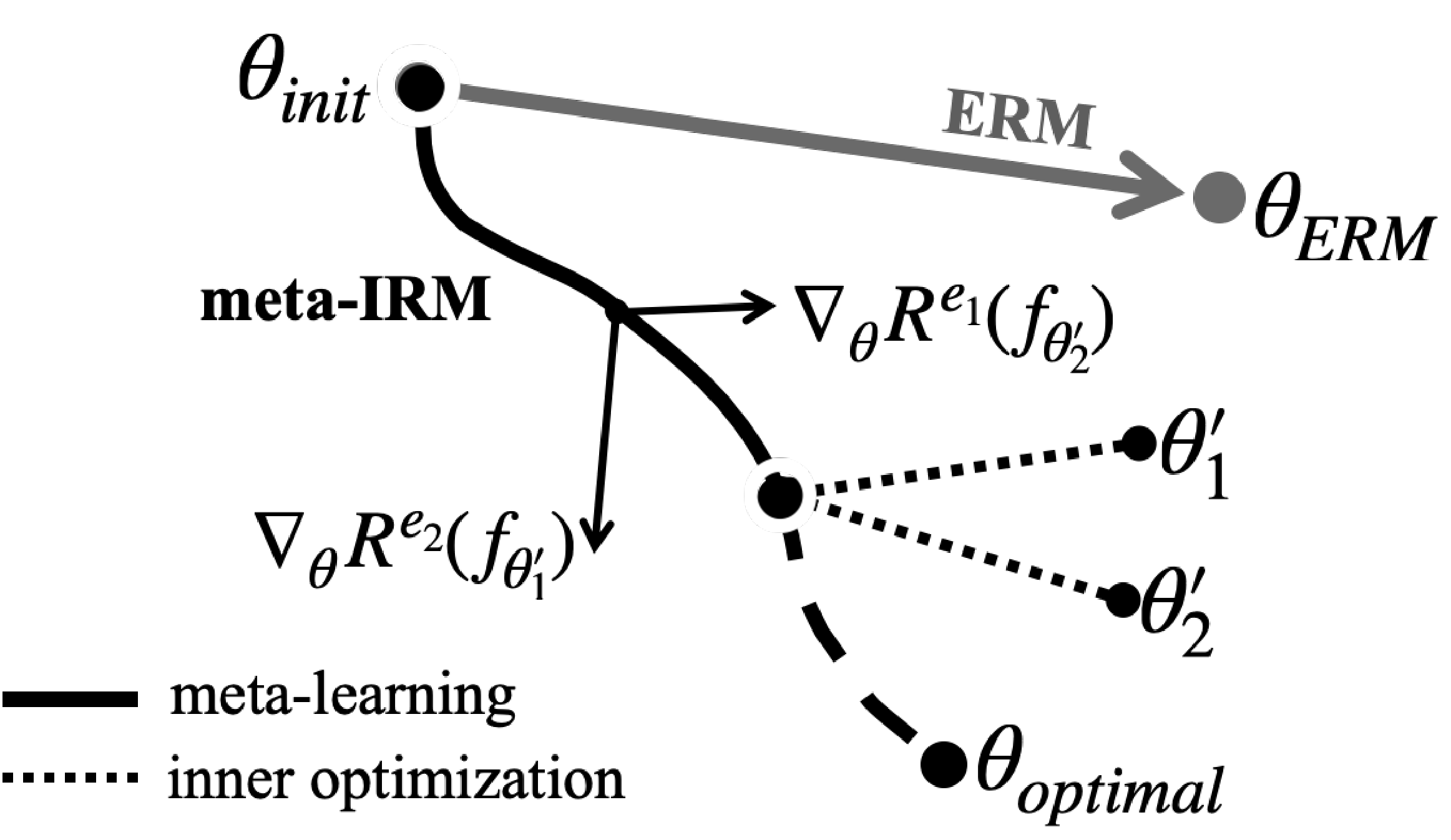
Meta-IRM의 학습 다이어그램. 각 environment에 adapted된 gradient를 결합하여 invariant feature 방향($\theta_{optimal}$)으로 수렴한다.
Method
IRM은 여러 training environment에 걸쳐 invariant한 predictor를 찾는 것이 목표다. Meta-IRM은 이를 MAML 프레임워크로 접근하며, 핵심 착안점은 inner loop와 outer loop에 서로 다른 training environment를 배정하는 것이다. Environment마다 spurious correlation의 방향이 다르므로, 서로 다른 environment에서 얻은 gradient를 결합하면 invariant feature 방향으로 수렴할 수 있다.
Meta-Learning Framework
MAML의 inner/outer 구조를 IRM에 대응시킨다. Inner loop에서는 한 environment에 적응하고, outer loop(meta-loss)에서는 다른 environment로 평가한다.
Inner optimization: 각 training environment \(e_i\) 에 대해 모델 파라미터를 적응시킨다:
\[\theta_i' = \theta - \alpha \nabla_\theta R^{e_i}(f_\theta)\]Meta-optimization: 적응된 파라미터 \(\theta_i'\) 로 다른 environment \(e_j\) 에서의 meta-loss를 계산하여 \(\theta\) 를 업데이트한다:
\[\theta \leftarrow \theta - \beta \nabla_\theta \left\{ \sum_i \sum_j R^{e_j}(f_{\theta_i'}) + \lambda \sigma \right\}, \quad e_j \sim \mathcal{E}_{tr} \setminus e_i\]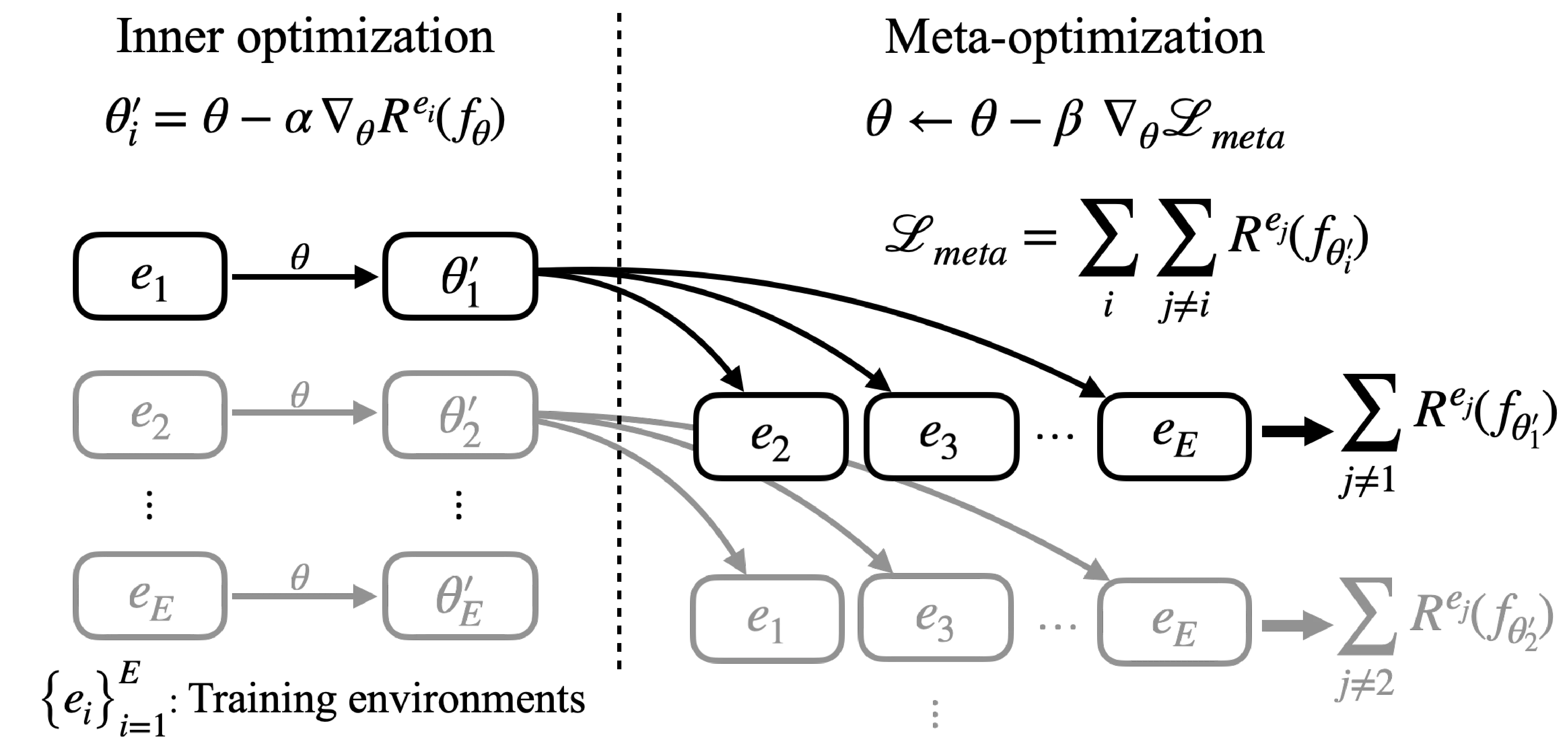
Meta-IRM 학습 과정. 모델 파라미터 $\theta$가 inner optimization에서 각 training environment에 적응되고, 적응된 파라미터로 다른 environment에서 meta-loss를 계산한다.
Auxiliary Standard Deviation Loss
Meta-loss의 표준편차 \(\sigma\) 를 보조 손실로 추가하여, 모든 environment에서 균일한 성능을 달성하도록 유도한다. 이 정규화는 학습 안정성을 높이고 수렴 속도를 개선한다.
Results
Colored MNIST
Test accuracy (%) on Colored MNIST. $p_e=0.9$이 OOD 환경 (color-label 상관관계 역전).
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| ERM | 88.6 ± 0.3 | 79.7 ± 0.6 | 16.4 ± 0.8 |
| IRMv1 | 71.4 ± 0.9 | 70.8 ± 1.0 | 66.9 ± 2.5 |
| MM-REx | 70.8 ± 1.5 | 70.4 ± 2.0 | 66.1 ± 4.9 |
| V-REx | 71.5 ± 0.8 | 71.1 ± 0.9 | 68.6 ± 1.2 |
| meta-IRM (Ours) | 70.9 ± 0.9 | 70.8 ± 1.0 | 70.4 ± 0.9 |
| Random | 50 | 50 | 50 |
| ERM (grayscale) | 72.6 ± 0.3 | 72.7 ± 0.3 | 73.0 ± 0.5 |
| Optimal | 75 | 75 | 75 |
meta-IRM(70.4%)은 V-REx(68.6%), IRMv1(66.9%), MM-REx(66.1%)를 모두 상회하며, 이론적 최적값(75%)에 가장 근접한다. 특히 OoD에서의 표준편차가 0.9로 다른 방법들(IRMv1 2.5, MM-REx 4.9)보다 현저히 낮아, 안정적으로 invariant feature를 학습하고 있음을 보여준다. ERM (grayscale)은 spurious feature가 제거된 이미지로 학습한 참조 지점(73.0%)으로, meta-IRM이 이에 근접함은 color spurious correlation을 거의 완전히 배제했음을 시사한다.
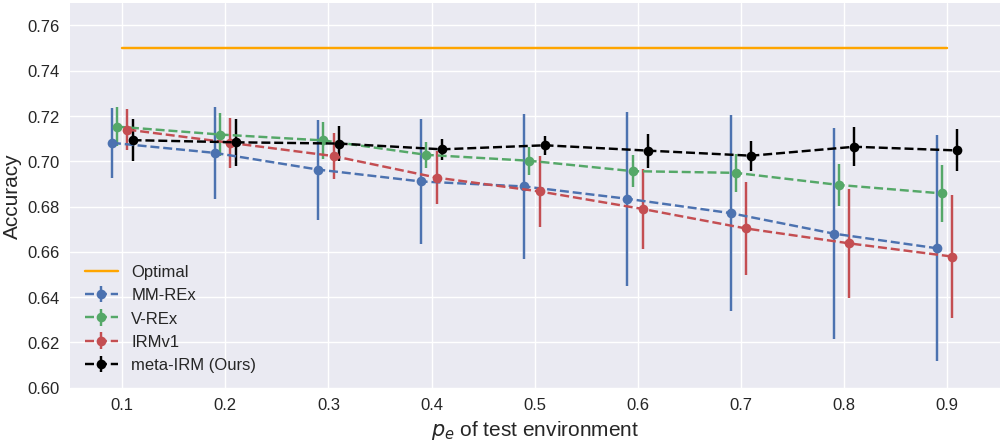
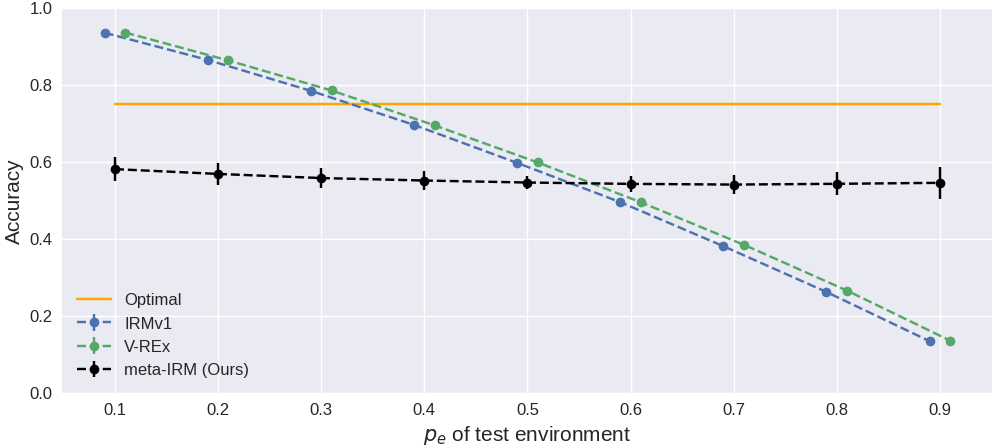
다양한 test environment ($p_e$ 0.1~0.9)에서의 정확도.
Multi-Class Problem
클래스 수가 증가하면 spurious correlation의 구조가 복잡해지며, meta-IRM의 이점이 더욱 두드러진다.
Multi-class Colored MNIST ($k$=5, 10) test accuracy (%).
| Algorithm | # Classes | Train | Test (OOD) |
|---|---|---|---|
| ERM | 5 | 95.2 ± 0.2 | 41.0 ± 0.6 |
| IRMv1 | 5 | 82.2 ± 0.4 | 62.0 ± 2.4 |
| meta-IRM (Ours) | 5 | 76.4 ± 1.4 | 74.0 ± 3.6 |
| Random | 5 | 20 | 20 |
| ERM (grayscale) | 5 | 73.2 ± 0.2 | 71.7 ± 0.4 |
| ERM | 10 | 92.6 ± 0.2 | 39.2 ± 0.9 |
| IRMv1 | 10 | 83.4 ± 0.5 | 58.6 ± 2.5 |
| meta-IRM (Ours) | 10 | 79.5 ± 0.6 | 73.4 ± 3.2 |
| Random | 10 | 10 | 10 |
| ERM (grayscale) | 10 | 73.2 ± 0.1 | 71.9 ± 0.5 |
| Optimal | — | 75 | 75 |
10 클래스 설정에서 meta-IRM(73.4%)은 IRMv1(58.6%)을 14.8%p 상회하며, ERM (grayscale) 참조 지점(71.9%)도 초과한다. 이는 클래스 수가 늘어날수록 IRMv1의 penalty term이 불충분해지는 반면, meta-IRM의 cross-environment evaluation은 문제 복잡도에 관계없이 invariant feature로의 수렴을 유도할 수 있음을 보여준다.
Insufficient Data
Training data가 절반(12,500)으로 줄었을 때, IRM 계열 방법들의 성능이 얼마나 유지되는지 평가한다.
Training data 감소 시 test accuracy (%). 25,000 → 12,500 per environment.
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 73.2 ± 1.6 | 71.7 ± 1.3 | 58.5 ± 2.5 |
| V-REx | 75.0 ± 0.8 | 73.4 ± 0.6 | 61.3 ± 1.4 |
| meta-IRM (Ours) | 70.6 ± 1.5 | 70.5 ± 1.6 | 68.3 ± 2.3 |
| Optimal | 75 | 75 | 75 |
데이터가 절반으로 줄었을 때, IRMv1은 66.9% → 58.5%로 8.4%p 하락하는 반면, meta-IRM은 70.4% → 68.3%로 2.1%p만 하락한다. Meta-learning 기반의 최적화가 데이터 부족 환경에서도 효율적으로 invariant feature를 추출함을 보여준다.
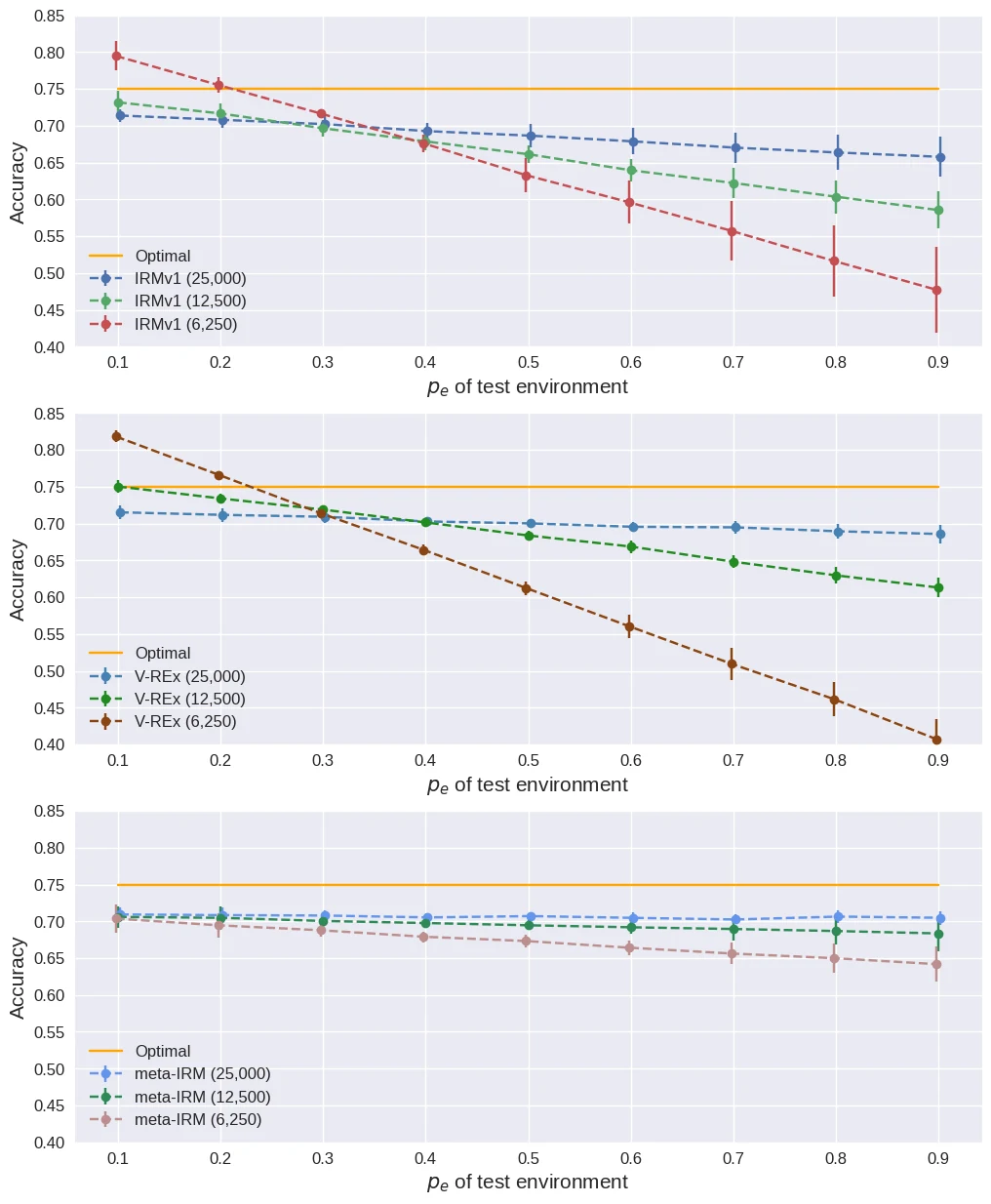
Training data 감소에 따른 영향 (25,000 → 12,500 → 6,250).
Two Spurious Features
Spurious correlation이 2개(color + patch)이고 environment가 2개인 경우다. 이 설정에서 IRMv1의 이론적 보장은 성립하지 않는다(spurious feature 수 > environment 수).
| Algorithm | \(p_e=0.1\) | \(p_e=0.2\) | \(p_e=0.9\) (OOD) |
|---|---|---|---|
| IRMv1 | 93.5 ± 0.2 | 86.4 ± 0.3 | 13.4 ± 0.3 |
| V-REx | 93.6 ± 0.4 | 86.3 ± 0.3 | 13.5 ± 0.3 |
| meta-IRM (Ours) | 58.1 ± 3.1 | 56.8 ± 2.9 | 54.5 ± 4.0 |
| Optimal | 75 | 75 | 75 |
IRMv1과 V-REx는 13.4–13.5%로 랜덤(50%) 이하로 하락하며 사실상 실패한다. 이는 두 spurious feature를 모두 활용하여 in-distribution에서 높은 정확도를 달성하되, OoD에서 두 correlation이 동시에 역전되면서 성능이 급격히 하락하는 것이다. meta-IRM은 54.5%로 최적에는 미치지 못하나, 랜덤 이상의 성능을 유지하여 invariant feature 방향의 학습이 부분적으로 이루어지고 있음을 보여준다.
두 가지 spurious feature (color + patch) 존재 시 각 알고리즘의 test environment별 정확도.
PunctuatedSST-2 (NLP)
Colored MNIST의 원리가 자연어 처리에서도 작동하는지를 PunctuatedSST-2로 검증한다. 감정 분석 태스크에서 구두점("!" vs “.")이 spurious feature로 작용하는 설정이다.
PunctuatedSST-2 test accuracy (%). $\eta_e$는 label noise 비율.
| Algorithm | \(\eta_e\) | Test (OOD) |
|---|---|---|
| ERM | 0.25 | 30.7 ± 1.5 |
| IRMv1 | 0.25 | 62.0 ± 1.9 |
| meta-IRM (Ours) | 0.25 | 62.2 ± 1.8 |
| ERM (vanilla) | 0.25 | 62.3 ± 0.5 |
| Optimal | 0.25 | 75 |
| ERM | 0 | 56.2 ± 2.9 |
| IRMv1 | 0 | 67.4 ± 1.4 |
| meta-IRM (Ours) | 0 | 73.0 ± 0.7 |
| ERM (vanilla) | 0 | 76.7 ± 2.7 |
| Optimal | 0 | 100 |
Label noise가 없는 설정(\(\eta_e=0\) )에서 meta-IRM(73.0%)은 IRMv1(67.4%)을 5.6%p 상회하며, 구두점 spurious feature가 없는 vanilla SST-2에서 학습한 ERM (vanilla) 참조점(76.7%)에 근접한다. Label noise가 있는 경우(\(\eta_e=0.25\) )에는 meta-IRM(62.2%)이 ERM (vanilla, 62.3%)과 사실상 동률이며 IRMv1과도 근접한다 — label noise가 invariant feature 자체의 정보량을 제한하기 때문에 방법 간 차이가 사라지고, 구두점 spurious correlation을 배제한 것이 얻을 수 있는 상한에 이미 도달한 것으로 해석할 수 있다.
Ablation Study
| Variant | \(p_e=0.1\) | \(p_e=0.9\) (OOD) |
|---|---|---|
| w/o std. loss | 73.0 ± 0.8 | 64.2 ± 3.2 |
| First-order approx. | 62.6 ± 5.5 | 59.1 ± 6.3 |
| Same env. (inner = meta) | 89.3 ± 1.6 | 13.6 ± 6.6 |
| meta-IRM (Full) | 70.9 ± 0.9 | 70.4 ± 0.9 |
| Optimal | 75 | 75 |
Same environment(inner = meta) 변형은 13.6%로 ERM 수준의 실패를 보인다. Inner loop와 outer loop에 서로 다른 environment를 배정하는 것이 meta-IRM의 핵심 메커니즘임을 확인하는 결정적 결과이다. First-order approximation은 second-order gradient 정보의 손실로 인해 성능과 안정성이 모두 저하된다(59.1% ± 6.3). 표준편차 loss의 제거는 OoD 성능을 6.2%p 하락시키며 실행 간 표준편차도 키운다(3.2 vs 0.9).