Jaesin Ahn, Chaehyeon Lee, Jun-Hyun Bae, Junho Yim, Heechul Jung
Kyungpook National University · LG Energy Solution
8th place out of 1,121 teams
Abstract
Recently, machine unlearning has received considerable attention, in the context of responsible artificial intelligence and privacy regulations. This technical report introduces novel machine unlearning methods, such as stochastic re-initialization, knowledge preserving loss, Gaussian noise, and forget-remember cycle. We present successful unlearning results, validated in the NeurIPS 2023 Machine Unlearning Challenge, accompanied by visualizations of logit distributions and several interim experiments.
Overview
Forget set에 접근하지 않고 retain set만으로, 재학습 없이 특정 데이터의 영향을 효과적으로 제거하는 machine unlearning 방법을 제안한다.
- Stochastic re-initialization — 모델 레이어를 랜덤으로 선택하여 재초기화함으로써, 특정 데이터에 대한 기억을 확률적으로 파괴한다.
- Knowledge preserving — 원본 모델의 출력을 MSE loss로 재현하여 retain set에 대한 성능을 유지한다.
- Forget-remember cycles — Forgetting과 remembering phase를 3–4회 반복하여, 점진적으로 re-initialization 비율을 높이면서 retain set 성능을 유지한다.

전체 아키텍처. (a) Retain set 이미지에 Gaussian noise 추가, (b) 랜덤 레이어 stochastic re-initialization, (c) 원본 모델과의 knowledge preserving loss 계산, (d) (a)–(c)를 $n$ cycle 반복.
Evaluation
대회의 평가 메트릭은 단순한 정확도가 아닌 분포 기반 unlearning quality로, 다음과 같이 정의된다:
\[\text{Score} = F \times \frac{RA_U}{RA_R} \times \frac{TA_U}{TA_R}\]\(F\) 는 forgetting quality, \(RA_U / RA_R\) 은 retain accuracy 비율(unlearned vs retrained), \(TA_U / TA_R\) 은 test accuracy 비율이다. 핵심은 이 메트릭이 512회 독립 실행의 출력 분포를 평가한다는 점이다. 단일 실행의 성능이 아니라 실행 간 분포가 retrained model의 분포와 유사해야 하므로, 알고리즘에 적절한 수준의 randomness가 필요하다.
Method
Stochastic Re-initialization
모델의 일부 레이어를 랜덤으로 선택하여 re-initialize 한 뒤 retain set으로 fine-tune한다. Fisher information matrix (FIM) 기반의 선택이 직관적으로 합리적이나, 실제로는 FIM 기반 선택이 더 낮은 점수를 보인다. 이는 FIM이 매번 동일한 레이어를 선택하여 512회 실행 분포의 다양성이 부족해지기 때문이다. 랜덤 선택은 이 다양성을 자연스럽게 확보한다.
FC layer와 projection-shortcut layer는 클래스/해상도 정보를 담고 있어 re-initialization 대상에서 제외한다.
Knowledge Preserving Loss
Retain set에 대해서는 원본 모델의 출력을 재현하도록 MSE loss로 학습한다:
\[\mathcal{L}_{KP} = \mathbb{E}\left[|f_O(\mathbf{I}'_R) - f_U(\mathbf{I}'_R)|^2\right]\]Cross-entropy(0.0653)나 L1 loss(0.0326) 대비 MSE loss(0.0680)가 가장 높은 점수를 기록하며, 원본 모델의 출력 분포를 보존하는 데 가장 효과적이다.
Gaussian Noise Augmentation
Retain set 이미지에 Gaussian noise를 추가하여 randomness를 확보하면서도 robust한 knowledge preserving 효과를 얻는다. Ablation에서는 \(\sigma=0.1\) 이 최적(\(0.06532\) )이며, \(\sigma=0.05\) (\(0.06333\) ) 및 \(\sigma=0.15\) (\(0.05907\) )보다 우수하다. Vertical flip(\(0.02505\) ), random crop/cutout(\(0.00001\) )은 데이터 분포를 심하게 왜곡하여 점수가 급락하는 반면, Gaussian noise는 분포를 크게 변형하지 않으면서 소폭의 개선을 가져온다. 최종 제출 알고리즘에서는 512회 실행의 분포 다양성과 추가적인 경험적 튜닝을 고려하여 production에서 \(\sigma=0.01\) 을 사용한다.
Forget-Remember Cycles
Re-initialization 비율을 단순히 높이면 모델이 과도하게 망각한다. 단일 cycle에서 비율을 10% → 20%로 늘리면 오히려 점수가 하락한다(0.0680 → 0.0656). 대신 3–4 cycle로 forgetting과 remembering을 반복하면, 총 re-initialization 비율을 점진적으로 높이면서도 retain set 성능을 유지할 수 있다. 이 cycle 구조가 가장 큰 성능 향상을 가져온 요소로, 단일 cycle(0.0680)에서 2 cycle(0.0844), 3 cycle(0.0856)로 점수가 점진적으로 상승한다.
알고리즘 하이퍼파라미터. 1st 알고리즘은 3 cycles [1, 2, 2] epochs에 cosine learning rate scheduler(\(init\_lr=0.001\)
, \(T\_max=2\)
)를 사용한다. 2nd 알고리즘은 4 cycles [2, 1, 1, 1] epochs에 epoch별 학습률 [0.0005, 0.001, 0.001, 0.001, 0.001]을 사용한다. 두 알고리즘 모두 선택 풀에서 6개 레이어를 복원 추출(with replacement) 로 선택한다. Gaussian noise는 평균 0, 표준편차 0.01의 분포에서 샘플링한다.
Results
Quantitative
| Model | Score |
|---|---|
| Negrad | 0.0001 (±0.0001) |
| Fine-tune (baseline) | 0.0464 (±0.0031) |
| 1st Algo. (ours) | 0.0939 (±0.0065) |
| 2nd Algo. (ours) | 0.0929 (±0.0051) |
| 1st Algo. (ours, best) | 0.1020 |
| 2nd Algo. (ours, best) | 0.1024 |
Ablation Study
각 구성 요소가 최종 성능에 미치는 영향을 순차적으로 분석한다.
Re-initialization.
| 실험 | Score |
|---|---|
| Fine-tune | 0.0496 |
| + Stochastic Re-init (random) | 0.0617 |
| + FIM-based Re-init | 0.0486 |
Data Augmentation (10% Re-init, 3 ep 기준).
| Input Data | Score |
|---|---|
| Clean Image | 0.06172 |
| Vertical Flip | 0.02505 |
| Random Crop | 0.00001 |
| Cutout | 0.00001 |
| + Gaussian Noise (\(\sigma=0.05\) ) | 0.06333 |
| + Gaussian Noise (\(\sigma=0.15\) ) | 0.05907 |
| + Gaussian Noise (\(\sigma=0.1\) ) | 0.06532 |
Loss Functions.
| Loss | Score |
|---|---|
| CE Loss | 0.0653 |
| L1 Loss | 0.0326 |
| MSE Loss | 0.0680 |
Number of Cycles.
| Cycles | Selection Ratio | Score |
|---|---|---|
| 1 (2 ep) | 10% | 0.0680 |
| 1 (2 ep) | 20% | 0.0656 |
| 2 (2-2 ep) | ~20% | 0.0844 |
| 3 (1-2-2 ep) | ~30% | 0.0856 |
Selection Pool (Layer Exclusion).
| Excluded Layers | Selection Ratio | Score |
|---|---|---|
| None | ~30% | 0.0856 |
| FC only | ~30% | 0.0926 |
| FC & Projection-shortcut | ~30% | 0.0969 |
FIM 기반 re-initialization(0.0486)은 fine-tune only(0.0496)보다 오히려 나쁘다. 이는 FIM이 항상 동일한 중요 파라미터를 선택하여 512회 실행의 분포 다양성이 부족해지기 때문이다. 반면 랜덤 선택(0.0617)은 자연스럽게 다양한 분포를 생성한다. 개별 요소 중에서는 **cycle 구조(0.0680 → 0.0844 → 0.0856)**와 **layer 선택 풀 제한(0.0856 → 0.0926 → 0.0969)**이 가장 큰 향상을 가져온다.
추가로, layer-wise 선택(0.0856)이 element-wise 선택(0.0575)보다 현저히 우수하다. 이는 layer 단위의 re-initialization이 모델의 기능적 단위를 적절히 초기화하는 반면, element-wise는 레이어 내 parameter 간의 학습된 관계를 파괴하기 때문으로 해석된다.
Logit Distribution
Forget set과 retain set에서의 logit 분포를 비교하면, 제안 방법이 fine-tuning 대비 retrained model의 분포에 훨씬 가깝다.
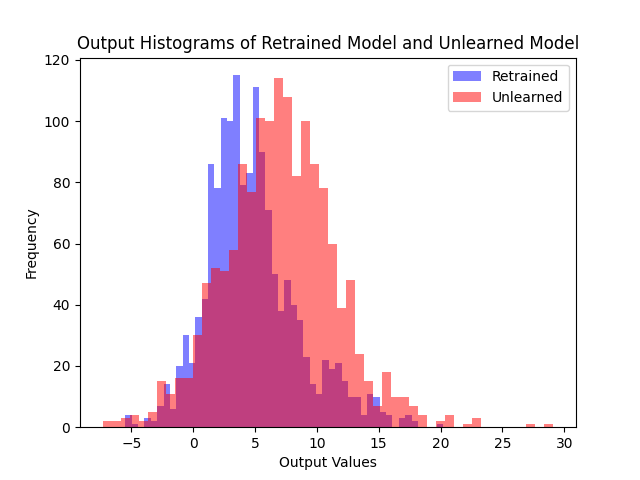
(a) Fine-tune
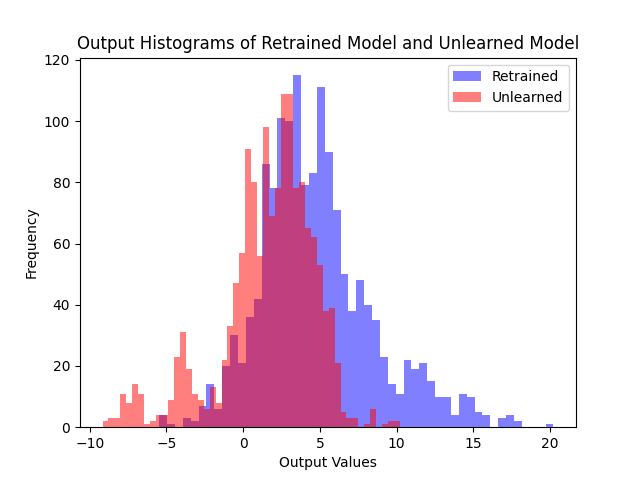
(b) 1st Algo.

(c) 2nd Algo.
Forget set의 logit 분포. Fine-tune 대비 두 제안 알고리즘 모두 retrained model의 분포에 훨씬 가깝고, 2nd 알고리즘이 1st와 유사한 형태를 보인다.
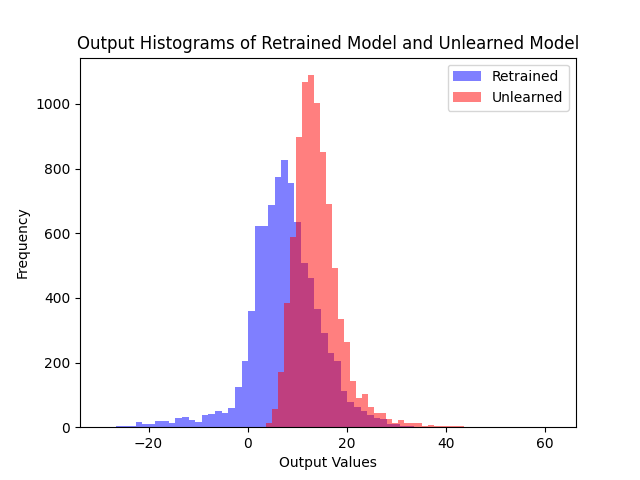
(a) Fine-tune
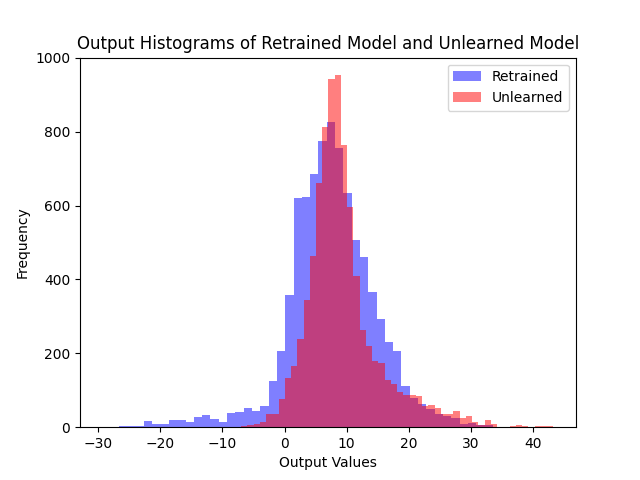
(b) 1st Algo.

(c) 2nd Algo.
Retain set의 logit 분포. 두 알고리즘 모두 retain set에서도 retrained model과 유사한 출력을 유지한다.